https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
Abstract
자연어 이해는 텍스트 함의, 질의응답, 의미 유사도 평가, 문서 분류 등 다양한 작업을 포함한다. 대규모 비지도 텍스트 데이터는 풍부하지만 이러한 작업을 학습하기 위한 라벨된 데이터는 부족하다. 이로 인해 지도학습 기반 모델은 충분한 성능을 내기 어렵다. 우리는 다양한 비지도 텍스트 데이터로 언어 모델을 사전 학습(pre-training)한 뒤 각 작업에 대해 지도학습 fine-tuning을 수행하면 큰 성능 향상을 얻을 수 있음을 보인다. 기존 방법들과 달리 우리는 fine-tuning 단계에서 task-aware 입력 변환을 사용하여 모델 구조를 거의 변경하지 않고도 효과적인 전이를 달성한다. 우리는 다양한 자연어 이해 벤치마크에서 이 방법의 효과를 입증하였다. 우리의 모델은 task-specific 구조를 사용하는 기존 모델보다 성능이 뛰어나며, 12개 작업 중 9개에서 state-of-the-art를 달성하였다.
1 Introduction
자연어 처리(NLP)에서 raw text로부터 효과적으로 학습하는 능력은 지도학습에 대한 의존도를 줄이기 위해 매우 중요하다. 대부분의 딥러닝 모델은 많은 양의 라벨된 데이터에 의존하는데, 이는 데이터가 부족한 분야에서는 적용이 어렵다. 이런 상황에서 비지도 데이터에서 언어 정보를 학습할 수 있는 모델은 라벨 데이터를 추가로 수집하는 것보다 더 효율적이다. 또한 충분한 라벨 데이터가 존재하는 경우에도, 비지도 학습으로 좋은 표현을 미리 학습하면성능 향상을 가져올 수 있다. 지금까지 성공적인 예는 사전 학습된 단어 임베딩을 활용하는 것이다.
그러나 단어 수준 이상의 정보를 활용하는 것은 어렵다. 그 이유는 어떤 학습 목표가 좋은 텍스트 표현을 학습하는데 가장 효과적인지 불명확하다. 그리고 학습된 표현을 실제 task로 어떻게 전이할지에 대한 방법이 정립되어 있지 않다. 기존 방법들은 task마다 다른 구조 설계하거나 복잡한 학습 방식, 보조 목표를 사용하는 등 다양한 접근 시도해왔다. 하지만 이러한 불확실성 떄문에 효과적인 semi-supervised 학습 방법을 만들기 어려웠다.
본 논문에서는 비지도 pre-training과 각 task에 맞게 지도 fine-tuning을 결합한 semi-supervised 접근을 제안한다. 목표는 다양한 task에 적은 수정만으로 적용 가능한 범용 표현을 학습하는 것이다. 모델 구조로는 긴 문맥 잘 처리하고 다양한 task에서 좋은 전이 성능 제공하는 Transformer를 사용한다. 또한 structured input을 하나의 토큰 시퀀스로 변환하는 방식을 사용하여 모델 구조 거의 변경하지 않고 다양한 task에 적용한다.
2 Related Work
1. Semi-supervised learning for NLP : 본 연구는 자연어 처리에서의 반지도 학습 범주에 속한다. 초기 연구들은 라벨이 없는 데이터로부터 단어 또는 구 수준의 통계를 계산하고, 이를 지도학습 모델의 feature로 사용하였다. 최근에는 비지도 데이터로 학습된 word embedding을 활용하여 여러 NLP 작업에서 성능을 향상시키는 방법이 널리 사용되고 있다.
2. 문장/구 수준 표현 : 최근 연구들은 단어를 넘어서 문장이나 구 단위의 의미 표현을 학습하는 방법을 제안하였다.
3. Unsupervised pre-training : 비지도 사전학습은 반지도 학습의 한 형태로 모델을 더 잘 학습시키기 위한 좋은 초기값을 찾는 것을 목표로 한다. 모델의 일반화 성능을 향상시키는 효과가 있음이 확인되었다.
4. 기존 language model 기반 방법 : 가장 유사한 연구는 언어 모델로 pre-training을 한 뒤 fine-tuning하는 방식이다. 하지만 기존 연구들은 LSTM을 사용하기 때문에 짧은 문맥만 학습할 수 있는 한계가 있다. 반면 본 논문은 Transformer 사용하여 더 긴 문맥 정보 학습 가능하다.
5. 다른 접근과의 차이 : 일부 연구는 pre-trained 모델의 hidden representation을 추가 feature로 사용하는 방법을 사용한다. 하지만 이 경우 task마다 새로운 파라미터가 많이 필요하다. 본 논문은 모델 구조 거의 변경하지 않고도 전이 학습 가능하다.
6. Auxiliary training objectives : 또 다른 방법은 보조 학습 목표를 추가하는 것이다. 예를 들어 POS tagging이나 NER 같은 작업을 함께 학습하거나, language modeling을 보조 목표로 사용하는 방식이 있다. 본 논문은 pre-training만으로도 충분한 언어 정보 학습됨을 확인하였다.
3. Framework
학습 과정은 두 단계로 이루어진다. 대규모 텍스트 데이터로 언어 모델 학습 -> 라벨링된 데이터 이용해 특정 task에 맞게 fine-tuning
3.1 Unsupervised pre-training

비지도 텍스트 코퍼스 U={u1,...,un}가 주어졌을 때 표준적인 language modeling objective를 사용하여 다음의 확률을 최대화하도록 학습한다. k는 window 사이즈를 의미, 조건부 확률 P는 파라미터를 가진 신경망으로 모델링된다. stochastic gradient descent(SGD)를 통해 학습된다. language model로 multi-layer Transformer decoder를 사용해 입력 토큰들에 대해 multi-head self-attention을 적용한 뒤 position-wise feed-forward layer를 거쳐 다음 단어의 확률 분포를 생성한다.

U는 문맥 토큰들 (u−k,...,u−1) , n은 layer 수, We는 단어 임베딩 행렬, Wp는 위치 임베딩 행렬을 의미한다.
3.2 Supervised Fine-tuning
모델을 학습한 이후, 지도학습 task에 맞게 조정(fine-tuning)한다. 라벨된 데이터셋 C를 가정하고 각 데이터는 입력 토큰 시퀀스 (x1,...,xm)과 해당 label 로 구성된다. 입력은 pre-trained 모델을 통과하여 마지막 Transformer layer의 출력 hl을 얻는다. 이후, 이 값을 새로운 linear layer에 넣어 label y를 예측한다. 목적함수도 최대화한다.
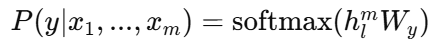

fine-tuning 과정에서 language modeling을 보조 objective로 함께 사용하는 것이 학습에 도움이 된다는 것을 발견하였다.
-> 일반화 성능 향상 + 학습 속도 증가
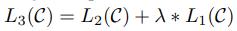
목적함수 최적화한다. fine-tuning 과정에서 추가되는 파라미터는 출력 layer의 Wy와 일부 delimiter token embedding 뿐이다.

왼쪽은 Transformer 구조와 학습 방식, 오른쪽은 다양한 task에 대해 입력을 token sequence 형태로 변환하는 방식이다. 모든 입력을 하나의 시퀸스로 변환한 뒤, linear + softmax를 통해 출력한다.
3.3 Task-specific input transformations
일부 작업(예: 텍스트 분류)은 앞에서 설명한 방식으로 그대로 fine-tuning이 가능하다. 하지만 질문응답이나 자연어 추론처럼 입력이 문장 쌍 또는 (문서, 질문, 답변)과 같은 구조를 가지는 경우에는 추가적인 처리가 필요하다. 우리의 pre-trained 모델은 연속된 텍스트 시퀀스를 기반으로 학습되었기 때문에, 이러한 구조화된 입력을 그대로 사용할 수 없다. 기존 연구에서는 전이된 표현 위에 task-specific 구조를 추가로 학습하는 방법을 사용하였다. 하지만 이러한 방식은 task마다 많은 구조적 변경을 필요로 하며, 추가적인 부분에서는 전이학습이 제대로 활용되지 않는다. 본 논문은 대신 구조화된 입력을 하나의 순서 있는 텍스트 시퀀스로 변환하는 방식을 사용한다. 이 방법을 통해 모델 구조를 크게 바꾸지 않고도 다양한 task에 적용할 수 있다.
Textual Entailment (문장 관계 판단) : premise(p)와 hypothesis(h)를 중간에 delimiter 토큰($)을 넣어 이어 붙인다.
-> [p ; $ ; h]
Similarity (문장 유사도) : 두 문장의 순서가 중요하지 않기 때문에 두 가지 순서를 모두 사용한다.
-> [s1 ; $ ; s2], [s2 ; $ ; s1]
Question Answering / Commonsense Reasoning : 문서(z), 질문(q), 답 후보들 {aₖ}가 주어진다. 각 답 후보마다 다음과 같이 입력을 구성한다. 각 시퀀스를 모델에 따로 넣은 뒤, softmax를 통해 최종 답을 선택한다.
-> [z ; q ; $ ; aₖ]
4.1 Experiments
4.1 Setup
unsupervised pre-training
약 7,000권 이상의 다양한 장르 책으로 구성된 BooksCorpus 데이터셋을 사용, 긴 문맥이 유지된 연속적인 텍스트로 이루어져 장거리 의존성 학습 가능 (1B Word Benchmark는 문장 단위로 섞여 있기 때문에 문맥 구조 깨지는 차이)
-> 이 데이터에서 perplexity 18.4라는 낮은 값을 달성
Model specifications
기본적으로 Transformer 구조 따름. 12-layer decoder-only Transformer, optimizer: Adam, 100 epoch 학습, L2 regularization 사용
Fine-tuning details
fine-tuning시에는 기본적으로 pre-training 설정을 그대로 사용한다. 대부분 task에서 3 epoch이면 충분
4.2 Supervised Fine-tuning
GPT 모델을 다양한 NLP task에 fine-tuning하여 성능을 평가하였다. 평가한 task는 크게 자연어 추론(NLI), 질문응답 및 상식 추론, 의미 유사도(패러프레이즈), 텍스트 분류로 구성된다. 전체적으로 GPT는 기존 RNN/BiLSTM 기반 모델보다 더 좋은 성능을 보였으며 특히 긴 문맥 처리와 문장 간 관계 이해에서 강점을 보였다. 또한 대부분의 task에서 복잡한 task-specific 구조 없이도 높은 성능을 달성하였다.
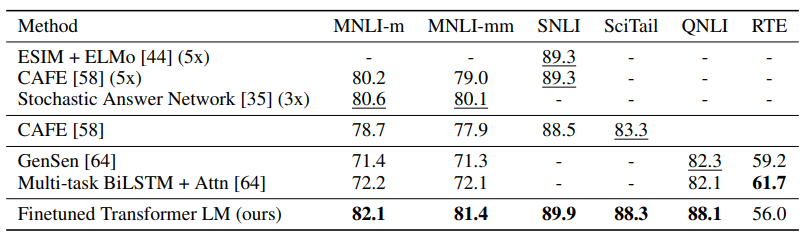
GPT(Finetuned Transformer LM)가 기존 NLI 모델들과 비교해서 얼마나 성능이 좋은지 보여주는 표다.
문장 관계 판단 task 학습 데이터와 비슷한 도메인 / 안 본 도메인 / 이미지 캡션 기반 데이터 / 과학 문제 기반 / 질문 문장 관계 / 작은 규모
-> 대부분 최고 성능, 긴 문맥과 문장 관계 이해 강함, 복잡한 구조 없어도 성능 우수, 작은 데이터셋에서는 약점 존재

짧은 이야기 마지막 문장 맞추기 / 중국 영어시험 기반 QA 중학교 수준 / 고등학교 수준
-> 상식 추론 매우 강함, 긴 문맥 처리 능력 뛰어남, 이야기 흐름과 논리 관계 이해 가능
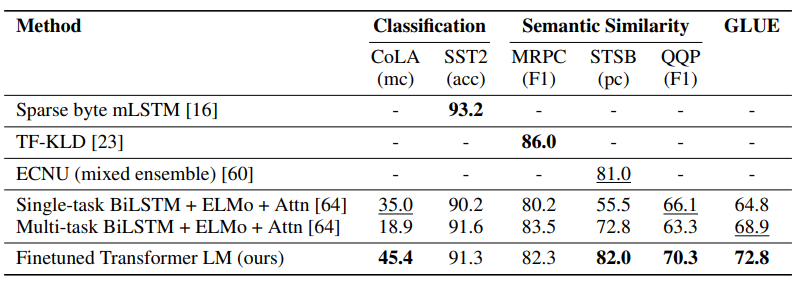
문법성 판단(CoLA) / 감정 분류(SST-2) / 문장 유사도(MRPC, QQP, STS-B)
-> 문법적 언어 이해 능력 우수, 문장 의미 및 패러프레이즈 관계를 효과적으로 학습, 다양한 NLP 분류 task에서도 높은 성능 달성
5. Analysis
GPT가 왜 잘 동작하는지 분석한다. 주요 분석 내용은 pre-training layer 전이 효과, zero-shot 성능 변화, Transformer vs LSTM 비교, pre-training의 중요성 등이다.
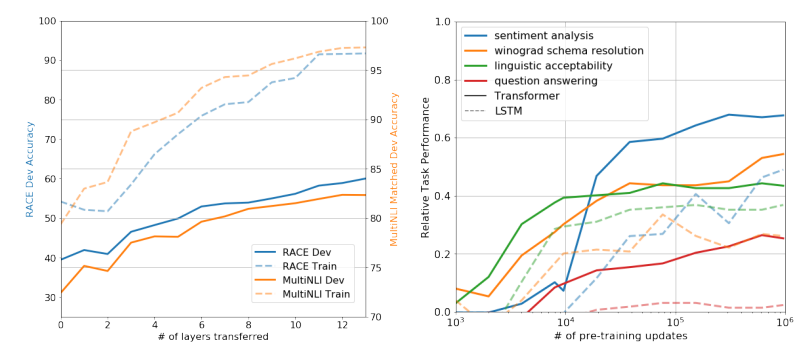
Layer Transfer Analysis
pre-training된 Transformer의 layer를 얼마나 많이 가져오는지에 따라 성능이 어떻게 변하는지 분석하였다. 결과적으로 embedding만 전이해도 성능 향상, Transformer layer를 더 많이 사용할수록 성능 증가, 전체 layer를 사용할 때 MultiNLI에서 최대 9% 향상을 보였다.
-> pre-trained 모델의 각 layer가 task 해결에 유용한 언어 정보를 학습하고 있음을 의미한다.
Zero-shot Behavior
Transformer language model이 왜 효과적인지 분석하기 위해 fine-tuning 없이(zero-shot) task를 수행하는 실험도 진행하였다. 결과적으로 학습이 진행될수록 zero-shot 성능도 꾸준히 향상, Transformer가 다양한 task 관련 기능을 자연스럽게 학습, LSTM보다 Transformer가 더 안정적인 transfer 성능을 보였다.
-> Transformer의 attention 구조가 전이학습에 도움을 준다는 것을 보여준다.

Auxiliary LM 제거 / Transformer 대신 LSTM 사용 / pre-training 제거
-> pre-training이 GPT 성능의 핵심 요소, Transformer가 LSTM보다 더 뛰어난 전이 성능 제공, auxiliary LM은 일부 큰 데이터셋에서만 성능 향상에 도움
6. Conclusion
generative pre-training과 discriminative fine-tuning을 통해 하나의 범용(task-agnostic) 모델로 강력한 자연어 이해를 수행하는 framework를 제안하였다. 긴 문맥이 포함된 다양한 텍스트 코퍼스로 pre-training되면서 풍부한 세계 지식과 장거리 의존성 처리 능력을 학습하게 된다. 이후 fine-tuning을 통해 다양한 task에 효과적으로 전이되었다. 비지도 pre-training을 이용해 지도학습 task 성능을 향상시키는 것은 오랫동안 머신러닝 분야의 중요한 목표였다. Transformer 구조와 긴 문맥 포함 텍스트 데이터가 매우 효과적이라는 점을 시사한다. 자연어 이해뿐 아니라 다양한 분야에서 비지도 학습 연구를 더욱 발전시키길 기대한다.