https://arxiv.org/abs/2010.11929
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to rep
arxiv.org
Abstract
Transformer 구조는 자연어처리, 즉 NLP 분야에서 사실상 표준 모델이 되었지만, 컴퓨터 비전 분야에서의 활용은 아직 제한적이었다. 기존 비전 연구에서는 attention을 CNN과 함께 사용하거나, CNN 구조의 일부 구성요소를 attention으로 대체하는 방식이 주로 사용되었다. 즉, 전체적인 CNN 구조는 그대로 유지하는 경우가 많았다.
하지만 이 논문에서는 이미지 인식 문제에서 반드시 CNN에 의존할 필요가 없다는 것을 보여준다. 이미지를 여러 개의 작은 패치로 나누고, 이 패치들의 sequence에 순수 Transformer를 직접 적용해도 이미지 분류 문제에서 매우 좋은 성능을 낼 수 있다는 것이다.
특히 Vision Transformer, 즉 ViT는 대량의 데이터로 사전학습한 뒤 ImageNet, CIFAR-100, VTAB과 같은 중간 규모 또는 작은 이미지 인식 벤치마크에 전이학습했을 때, 기존의 최신 CNN 모델들과 비교해도 뛰어난 결과를 달성했다. 또한 학습에 필요한 계산 자원은 훨씬 적게 사용했다.
1 INTRODUCTION
Self-attention 기반 구조, 특히 Transformer는 자연어처리 분야에서 가장 많이 선택되는 모델이 되었다. 대표적인 방식은 큰 텍스트 말뭉치로 먼저 사전학습을 하고, 이후 더 작은 특정 작업 데이터셋에 맞게 fine-tuning하는 것이다. Transformer는 계산 효율성과 확장성이 뛰어나기 때문에, 1000억 개 이상의 파라미터를 가진 매우 큰 모델도 학습할 수 있게 되었다. 또한 모델과 데이터셋의 크기가 계속 커지고 있음에도 성능 향상이 아직 한계에 도달했다는 신호는 보이지 않는다.
하지만 컴퓨터 비전 분야에서는 여전히 CNN 기반 구조가 주류이다. NLP에서 Transformer가 성공한 것에 영향을 받아, 여러 연구에서는 CNN과 self-attention을 결합하거나, CNN의 convolution 일부를 self-attention으로 대체하려고 했다. 그러나 convolution을 완전히 대체하려는 모델들은 이론적으로는 효율적일 수 있지만, 특수한 attention 구조를 사용하기 때문에 현대 하드웨어 가속기에서 효과적으로 확장하기 어려웠다. 그래서 대규모 이미지 인식 분야에서는 여전히 ResNet과 같은 전통적인 CNN 구조가 최신 성능을 내고 있었다.
이 논문은 NLP에서 Transformer가 대규모로 확장되며 성공한 것에서 영감을 받았다. 저자들은 가능한 한 최소한의 수정만으로 표준 Transformer를 이미지에 직접 적용하는 실험을 진행했다. 이를 위해 이미지를 여러 개의 patch로 나누고, 각 patch를 선형 임베딩한 sequence를 Transformer의 입력으로 제공했다. 즉, 이미지 patch를 NLP에서의 단어 token처럼 취급한 것이다. 그리고 이 모델을 지도학습 방식으로 이미지 분류 task에 학습시켰다.
그런데 데이터가 충분하지 않을 때는 일반화 성능이 CNN보다 좋지 않다. 그러나 ViT는 충분히 큰 규모로 사전학습한 뒤, 더 작은 데이터셋의 task로 전이학습했을 때 매우 뛰어난 성능을 보였다. 특히 공개 데이터셋인 ImageNet-21k 또는 Google 내부 데이터셋인 JFT-300M으로 사전학습했을 때, 기존 최신 모델에 근접하거나 이를 뛰어넘는 성능을 냈다.
2 RELATED WORK
Transformer는 Vaswani et al.이 2017년에 기계번역을 위해 제안한 모델이다. BERT는 self-supervised 방식의 denoising 사전학습을 사용했고, GPT 계열 모델들은 language modeling을 사전학습 task로 사용했다. 즉, 대규모 말뭉치로 먼저 학습한 뒤 특정 task에 fine-tuning하는 방식이 NLP에서 널리 사용되었다.
이미지에 self-attention을 단순하게 적용하려면, 이미지의 모든 픽셀이 다른 모든 픽셀을 참고해야 한다. 하지만 이 방식은 픽셀 수가 많아질수록 계산 비용이 제곱으로 증가하기 때문에 실제 크기의 이미지에는 적용하기 어렵다. 그래서 기존 연구들은 이미지 처리에 Transformer를 적용하기 위해 여러 가지 근사 방법을 사용했다. 예를 들어 Parmar et al.은 각 query pixel이 전체 이미지가 아니라 주변의 local neighborhood에 대해서만 self-attention을 수행하도록 했다. 이런 local multi-head dot-product self-attention 블록은 convolution을 완전히 대체할 수도 있다. 또 다른 연구인 Sparse Transformer는 이미지에 적용할 수 있도록 global self-attention을 더 효율적으로 근사하는 방식을 사용했다. 그 외에도 attention을 다양한 크기의 block 단위로 적용하거나, 극단적으로는 특정 축 방향으로만 attention을 적용하는 방식도 연구되었다.
이러한 특수한 attention 구조들은 컴퓨터 비전 task에서 가능성을 보여주었지만, 하드웨어 가속기에서 효율적으로 구현하려면 복잡한 엔지니어링이 필요하다는 문제가 있었다. 이 논문과 가장 관련이 깊은 연구는 Cordonnier et al.의 모델이다. 이 연구는 입력 이미지에서 2×2 크기의 patch를 추출하고, 그 위에 full self-attention을 적용했다. 이 모델은 ViT와 매우 유사하다. 하지만 ViT 논문은 여기서 더 나아가, 대규모 사전학습을 통해 vanilla Transformer가 최신 CNN 모델과 경쟁하거나 더 좋은 성능을 낼 수 있음을 보여준다. 또한 Cordonnier et al.은 2×2라는 매우 작은 patch를 사용했기 때문에 작은 해상도 이미지에만 적용 가능했지만, ViT는 중간 해상도의 이미지도 처리할 수 있다.
CNN과 self-attention을 결합하려는 연구들도 많이 있었다. 예를 들어 image classification을 위해 feature map에 attention을 추가하거나, object detection, video processing, image classification, unsupervised object discovery, text-vision task 등에서 CNN의 출력을 self-attention으로 추가 처리하는 방식들이 연구되었다. 또 다른 관련 연구로 image GPT, 즉 iGPT가 있다. iGPT는 이미지의 해상도와 color space를 줄인 뒤, 이미지 pixel에 Transformer를 적용했다. 이 모델은 generative model로 비지도학습 방식으로 학습되었고, 이후 학습된 representation을 fine-tuning하거나 linear probing하여 분류 성능을 평가했다. iGPT는 ImageNet에서 최대 72% 정확도를 달성했다.

Figure 1 : 모델 개요. 이미지를 고정된 크기의 패치들로 나누고, 각각의 패치를 선형 임베딩한다. 그다음 위치 임베딩을 추가한 뒤, 이렇게 만들어진 벡터들의 sequence를 표준 Transformer encoder에 입력한다. 분류를 수행하기 위해서는 일반적으로 사용되는 방식처럼, sequence에 추가적인 학습 가능한 “classification token”을 넣는다.
3 METHOD
모델 설계에서 기존 Transformer 구조를 가능한 한 그대로 따랐다. 의도적으로 단순한 구조를 사용한 장점은, 확장 가능한 Transformer 구조와 효율적인 구현 방식을 거의 그대로 사용할 수 있다는 점이다.
-> ViT는 이미지를 위해 새로운 구조를 만든 것X, NLP에서 쓰던 표준 Transformer를 이미지에 맞게 최소한만 수정해 사용한 모델
3.1 VISION TRANSFORMER (VIT)
기존 Transformer는 자연어처리에서 단어 token들의 1차원 sequence를 입력으로 받는다. 그러나 이미지는 2차원 구조를 가지기 때문에, ViT는 이미지를 Transformer에 입력하기 위해 먼저 고정 크기의 patch로 분할한다. 각 patch는 flatten 과정을 통해 1차원 벡터로 변환되고, 이후 학습 가능한 linear projection을 거쳐 Transformer 입력 차원에 맞는 patch embedding이 된다. ViT에서 patch는 NLP에서의 token과 유사한 역할을 한다. 예를 들어 문장에서 각 단어가 Transformer의 입력 token이 되는 것처럼, ViT에서는 이미지의 각 patch가 입력 token으로 사용된다. 전체 patch의 개수는 Transformer의 sequence length가 되며, patch 크기가 작을수록 sequence length가 길어져 계산량이 증가한다.
또한 ViT는 BERT의 [class] token과 유사한 classification token을 patch embedding sequence의 맨 앞에 추가한다. 이 classification token은 실제 이미지 patch는 아니지만, Transformer encoder를 통과하면서 전체 이미지 정보를 통합하는 역할을 한다. 최종 layer에서 classification token의 출력값은 이미지 전체를 대표하는 representation으로 사용되며, 이후 classification head를 통해 최종 class를 예측한다. 각 patch embedding에는 위치 정보를 보존하기 위해 position embedding이 더해진다. 이는 Transformer가 입력 sequence의 순서나 2차원 공간 구조를 직접적으로 알지 못하기 때문이다. 저자들은 복잡한 2D position embedding 대신 학습 가능한 1D position embedding을 사용했으며, 실험적으로 더 복잡한 위치 임베딩 방식이 뚜렷한 성능 향상을 제공하지 않았다.
Transformer encoder는 multi-head self-attention과 MLP block이 반복적으로 쌓인 구조이다. 각 block 앞에는 Layer Normalization이 적용되고, 각 block 뒤에는 residual connection이 사용된다. 이를 통해 ViT는 이미지의 각 patch 사이의 관계를 self-attention으로 학습할 수 있으며, CNN 없이도 이미지 분류에 필요한 전역적 정보를 통합할 수 있다. 따라서 ViT의 핵심 아이디어는 이미지를 patch sequence로 변환하고, 이를 표준 Transformer encoder에 입력하여 이미지 분류를 수행하는 것이다. 이 구조는 이미지 처리에 CNN의 convolution 구조를 사용하지 않고, NLP에서 사용되던 Transformer를 거의 그대로 컴퓨터 비전 문제에 적용했다는 점에서 중요한 의미를 가진다.
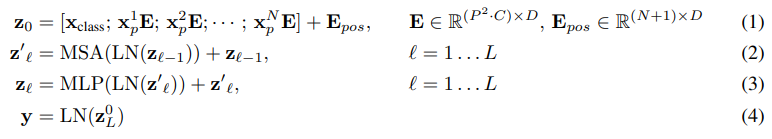
3.2 FINE-TUNING AND HIGHER RESOLUTION
일반적으로 우리는 ViT를 큰 데이터셋에서 먼저 사전학습한 뒤, 더 작은 downstream task에 fine-tuning한다. 이를 위해 사전학습 때 사용했던 prediction head를 제거하고, 새롭게 0으로 초기화된 D × K (downstream task class 개수) 크기의 feedforward layer를 붙인다. 또한 fine-tuning할 때는 사전학습 때보다 더 높은 해상도의 이미지를 사용하는 것이 도움이 되는 경우가 많다.
해상도가 더 높은 이미지를 입력할 때, patch size는 그대로 유지한다. 그러면 이미지 안에서 만들어지는 patch 개수가 더 많아지고, 결과적으로 Transformer에 들어가는 sequence length도 더 길어진다. Vision Transformer는 메모리 한계만 넘지 않는다면 다양한 sequence length를 처리할 수 있다. 하지만 문제가 하나 있다. 사전학습된 position embedding은 기존 해상도에 맞게 학습된 것이기 때문에, 더 높은 해상도의 이미지에서는 그대로 의미 있게 사용되기 어렵다.
그래서 저자들은 원래 이미지 안에서의 위치를 기준으로, 사전학습된 position embedding을 2D interpolation하여 새로운 해상도에 맞게 조정한다. 이 해상도 조정 과정과 patch extraction 과정이 ViT에 이미지의 2차원 구조에 대한 inductive bias를 수동으로 넣는 거의 유일한 부분이라고 설명한다.
4 EXPERIMENTS
ResNet, Vision Transformer(ViT), 그리고 hybrid 모델의 representation learning 능력을 평가한다. 각 모델이 얼마나 많은 데이터를 필요로 하는지 이해하기 위해, 서로 다른 크기의 데이터셋에서 모델을 사전학습하고, 여러 benchmark task에서 평가한다. 또한 모델을 사전학습하는 데 필요한 계산 비용을 고려했을 때, ViT는 매우 유리한 성능을 보인다. ViT는 더 낮은 사전학습 비용으로 대부분의 이미지 인식 benchmark에서 state-of-the-art, 즉 당시 최고 수준의 성능을 달성한다. 마지막으로 저자들은 self-supervision, 즉 자기지도학습을 사용한 작은 실험도 수행한다. 그 결과, self-supervised ViT가 앞으로 가능성이 있는 방향임을 보여준다.
4.1 SETUP
Datasets : 세 가지 규모의 사전학습 데이터셋을 사용했다. 첫 번째는 ILSVRC-2012 ImageNet 데이터셋이다. 이 데이터셋은 1,000개의 class와 약 130만 장의 이미지를 포함한다. 두 번째는 ImageNet-21k이다. 이는 ImageNet의 더 큰 버전으로, 21,000개의 class와 약 1,400만 장의 이미지를 포함한다. 세 번째는 JFT 데이터셋이다. JFT는 18,000개의 class와 약 3억 300만 장의 고해상도 이미지를 포함하는 대규모 데이터셋이다. 데이터 중복 제거를 수행했다. 또한 VTAB이라는 19개 task로 구성된 classification suite에서도 평가했다.
Natural: CIFAR, Pets 등 일반적인 자연 이미지 task
Specialized: 의료 이미지, 위성 이미지 등 특수 도메인 이미지 task
Structured: 위치 추정처럼 기하학적 이해가 필요한 task
Model Variants : ViT 모델 설정은 BERT에서 사용된 구조를 기반으로 한다. 세 가지 크기의 ViT 모델을 사용한다.
모델Layer 수Hidden size DMLP sizeHead 수Parameter 수
| 모델 | Layer 수 | Hidden size | MLP size | Head 수 | Parameter 수 |
| ViT-Base | 12 | 768 | 3072 | 12 | 86M |
| ViT-Large | 24 | 1024 | 4096 | 16 | 307M |
| ViT-Huge | 32 | 1280 | 5120 | 16 | 632M |
Training & Fine-tuning : Adam optimizer를 사용해 학습되었다. ResNet도 포함된다. Adam의 설정은 β1 = 0.9, β2 = 0.999이고, batch size는 4096이다. 또한 weight decay는 0.1로 비교적 크게 설정했다. 저자들은 이 설정이 모든 모델의 transfer 성능에 도움이 된다고 설명한다. 학습 과정에서는 learning rate warmup과 decay를 사용했다. Fine-tuning 단계에서는 모든 모델에 대해 momentum을 사용하는 SGD를 사용했고, batch size는 512로 설정했다. ImageNet 결과를 낼 때는 더 높은 해상도에서 fine-tuning했다. 예를 들어 ViT-L/16은 512 해상도, ViT-H/14는 518 해상도에서 fine-tuning했다.
Metrics : Fine-tuning accuracy는 사전학습된 모델을 각 데이터셋에 맞게 fine-tuning한 뒤 얻은 정확도이다. 즉, 실제 target task에 맞게 모델을 다시 학습시킨 후의 성능이다. Few-shot accuracy는 모델의 representation을 고정한 상태에서, 일부 training image만 사용해 간단한 선형 회귀 문제를 풀어 성능을 측정하는 방식이다. 이 방식은 full fine-tuning보다 계산 비용이 적기 때문에 빠른 평가에 사용된다.
4.2 COMPARISON TO STATE OF THE ART
먼저 가장 큰 모델인 ViT-H/14와 ViT-L/16을 기존의 최신 CNN 모델들과 비교했다. 첫 번째 비교 대상은 Big Transfer, BiT이다.
BiT는 큰 ResNet을 사용해 supervised transfer learning을 수행하는 모델이다. 두 번째 비교 대상은 Noisy Student이다.
Noisy Student는 큰 EfficientNet 모델이며, ImageNet과 JFT-300M에서 semi-supervised learning 방식으로 학습되었다.
이때 JFT-300M의 label은 제거한 상태로 사용되었다. 당시 기준으로 Noisy Student는 ImageNet에서 최고 성능을 보였고, BiT-L은 논문에서 보고하는 다른 데이터셋들에서 최고 성능을 보이던 모델이었다. 모든 모델은 TPUv3 하드웨어에서 학습되었으며, 저자들은 각 모델을 사전학습하는 데 걸린 TPUv3-core-days를 함께 보고했다. TPUv3-core-days란 학습에 사용한 TPUv3 core 수에 학습 일수를 곱한 값이다. 즉, 모델 학습에 들어간 계산 비용을 나타내는 지표이다.
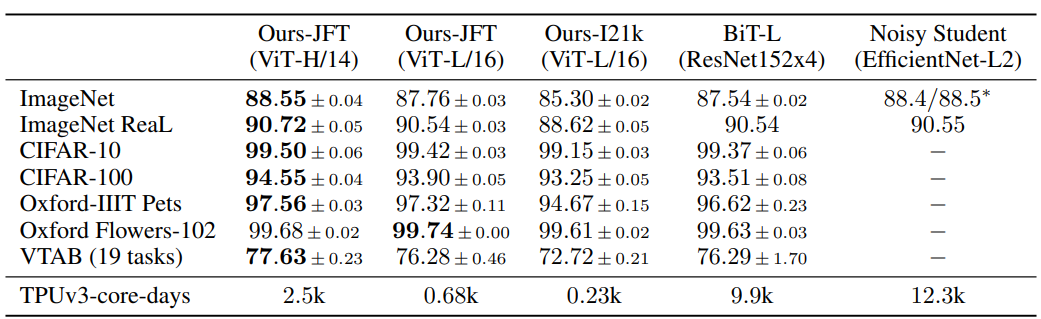
JFT-300M에서 사전학습한 더 작은 모델인 ViT-L/16은 같은 데이터셋에서 사전학습한 BiT-L보다 모든 task에서 더 좋은 성능을 보였다. 게다가 학습에 필요한 계산 자원은 훨씬 적었다. 더 큰 모델인 ViT-H/14는 성능을 더 향상시켰다. 특히 ImageNet, CIFAR-100, VTAB처럼 더 어려운 데이터셋에서 성능 향상이 두드러졌다. 흥미로운 점은 ViT-H/14도 기존 state-of-the-art 모델보다 훨씬 적은 계산량으로 사전학습되었다는 것이다. 다만 저자들은 사전학습 효율성이 모델 구조뿐 아니라 training schedule, optimizer, weight decay 같은 다른 요소의 영향을 받을 수 있다고 언급한다. 그래서 뒤의 4.4절에서 architecture별 성능과 계산량을 더 통제된 조건에서 비교한다.
마지막으로, 공개 데이터셋인 ImageNet-21k에서 사전학습한 ViT-L/16도 대부분의 데이터셋에서 좋은 성능을 보였다. 이 모델은 더 적은 자원으로 사전학습할 수 있었으며, 표준 cloud TPUv3 8-core를 사용하면 약 30일 정도에 학습할 수 있다고 설명한다.

Figure 2는 VTAB task를 세 그룹으로 나누어 성능을 비교한다. VTAB은 Natural, Specialized, Structured task로 구성된다.
이 그림에서는 ViT-H/14를 기존의 VTAB 최고 성능 방법들과 비교한다. 비교 대상은 BiT, VIVI, S4L이다. ViT-H/14는 Natural task와 Structured task에서 BiT-R152x4 및 다른 방법들보다 더 좋은 성능을 보였다. Specialized task에서는 상위 두 모델의 성능이 비슷했다.
4.3 PRE-TRAINING DATA REQUIREMENTS
Vision Transformer가 좋은 성능을 내기 위해 얼마나 많은 사전학습 데이터가 필요한지를 분석한다. ViT는 CNN에 비해 이미지에 특화된 inductive bias가 적기 때문에, 데이터셋 크기가 성능에 중요한 영향을 미칠 수 있다. 이를 확인하기 위해 두 가지 실험을 수행하였다.
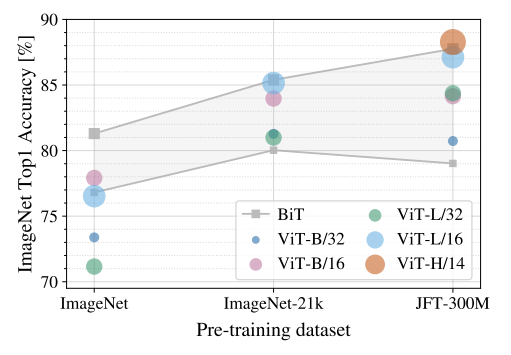

첫 번째 실험에서는 ViT를 ImageNet, ImageNet-21k, JFT-300M처럼 서로 다른 크기의 데이터셋에서 사전학습한 뒤 ImageNet으로 fine-tuning하여 성능을 비교하였다. 작은 데이터셋인 ImageNet에서 사전학습했을 때는 ViT-Large가 ViT-Base보다 낮은 성능을 보였으며, 전반적으로 BiT 기반 ResNet보다 낮은 성능을 기록하였다. 이는 ViT가 CNN보다 이미지에 대한 구조적 편향이 적기 때문에, 데이터가 부족할 경우 큰 모델일수록 overfitting되기 쉽다는 점을 보여준다.
-> 반면 ImageNet-21k로 사전학습했을 때는 ViT-Base와 ViT-Large의 성능이 비슷해졌고, JFT-300M으로 사전학습했을 때는 더 큰 ViT 모델의 성능 이점이 뚜렷하게 나타났다. 특히 대규모 데이터셋에서는 ViT가 BiT ResNet을 앞서는 결과를 보였다. 이는 충분한 데이터가 주어질 경우, ViT가 CNN의 inductive bias 없이도 이미지 인식에 필요한 패턴을 직접 학습할 수 있음을 의미한다.
두 번째 실험에서는 JFT-300M의 부분집합을 사용하여 데이터 크기에 따른 성능 변화를 더 세밀하게 분석하였다. 저자들은 9M, 30M, 90M, 300M 크기의 subset을 사용했고, 추가적인 regularization 없이 동일한 hyperparameter로 모델을 학습하였다. 이 설정은 regularization 효과가 아니라 모델 구조 자체의 데이터 요구 특성을 확인하기 위한 것이다.
-> 실험 결과, 작은 데이터셋에서는 ViT가 ResNet보다 더 쉽게 overfitting되었고 성능도 낮았다. 예를 들어 ViT-B/32는 ResNet50보다 계산 비용이 약간 낮음에도 9M subset에서는 훨씬 낮은 성능을 보였다. 그러나 데이터 크기가 90M 이상으로 증가하면 ViT가 ResNet보다 더 좋은 성능을 보이기 시작했다. 이는 작은 데이터에서는 convolutional inductive bias가 유리하지만, 큰 데이터에서는 모델이 필요한 패턴을 데이터로부터 직접 학습하는 것이 충분하며 오히려 더 효과적일 수 있음을 보여준다.
따라서 핵심은 ViT의 성능이 사전학습 데이터 규모에 크게 의존한다는 점이다. CNN은 이미지에 적합한 구조적 편향 덕분에 작은 데이터에서도 강점을 보이지만, ViT는 대규모 데이터셋에서 사전학습될 때 그 잠재력이 본격적으로 나타난다. 이는 ViT가 단순한 구조임에도 대규모 데이터와 결합될 경우 CNN 기반 모델을 능가할 수 있음을 뒷받침한다.
4.4 SCALING STUDY
JFT-300M에서 사전학습한 여러 모델을 대상으로, 서로 다른 모델 구조들의 scaling study를 수행했다. 이 설정에서는 데이터 크기가 모델 성능의 병목이 되지 않기 때문에, 각 모델의 사전학습 비용 대비 성능을 평가할 수 있다. 실험에 포함된 모델은 ResNet, Vision Transformer, Hybrid 모델이다. ResNet은 R50x1, R50x2, R101x1, R152x1, R152x2 등을 사용했고, ViT는 ViT-B/32, B/16, L/32, L/16, H/14 등을 사용했다. Hybrid 모델은 ResNet50과 ViT를 결합한 구조를 사용했다.

Figure 5는 전체 사전학습 계산량에 따른 transfer 성능을 보여준다. 결과적으로 몇가지 패천이 관찰되었다.
첫째, Vision Transformer는 성능과 계산량의 균형 측면에서 ResNet보다 우수했다.
ViT는 평균적으로 같은 성능을 얻기 위해 ResNet보다 약 2~4배 적은 계산량을 사용했다.
둘째, Hybrid 모델은 작은 모델 크기에서는 순수 ViT보다 약간 더 좋은 성능을 보였지만, 모델이 커질수록 그 차이는 사라졌다.
이는 CNN의 지역적 특징 처리 능력이 작은 모델에서는 도움이 되지만, 큰 모델에서는 순수 Transformer만으로도 충분히 학습할 수 있음을 의미한다.
셋째, ViT는 실험한 범위 안에서 아직 성능이 포화되지 않았다.
즉, 모델을 더 키우거나 더 많은 계산량을 사용하면 성능이 더 향상될 가능성이 있다.
4.5 INSPECTING VISION TRANSFORMER
Vision Transformer가 이미지 데이터를 내부적으로 어떻게 처리하는지를 분석한다. 저자들은 ViT의 학습된 representation, position embedding, attention pattern을 살펴봄으로써, ViT가 이미지의 공간적 구조와 의미 있는 영역을 실제로 학습하는지 확인하였다.
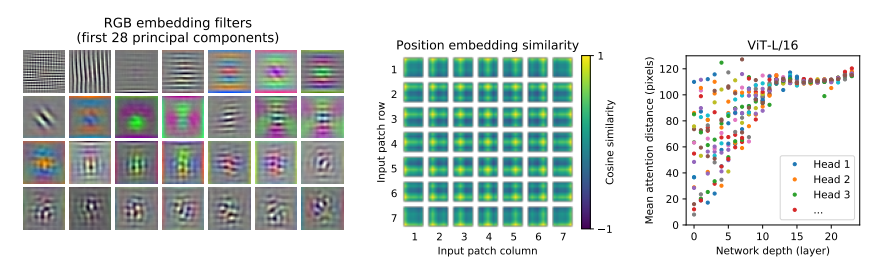
먼저 ViT의 첫 번째 linear projection layer를 분석한 결과, 학습된 embedding filter가 patch 내부의 세밀한 구조를 표현하는 basis function과 유사한 형태를 보였다. 이는 ViT가 이미지 patch로부터 기본적인 시각적 특징을 학습하고 있음을 의미한다.
다음으로 position embedding을 분석한 결과, 가까운 위치의 patch일수록 position embedding이 더 비슷하게 학습되는 경향이 나타났다. 또한 같은 행이나 열에 위치한 patch들이 유사한 embedding을 가지는 구조도 관찰되었다. 이는 ViT가 명시적인 2D 구조를 강하게 내장하고 있지 않음에도, 학습을 통해 이미지의 공간적 관계를 어느 정도 획득한다는 것을 보여준다.
마지막으로 저자들은 attention distance를 분석하였다. Attention distance는 self-attention이 이미지 공간에서 평균적으로 얼마나 먼 위치의 정보를 통합하는지를 나타내며, CNN의 receptive field와 유사한 개념이다. 분석 결과, 일부 attention head는 낮은 layer부터 이미지 전체에 걸쳐 정보를 통합했으며, 다른 head들은 가까운 영역 중심의 지역적 attention을 수행하였다. 또한 layer가 깊어질수록 attention distance가 증가하는 경향이 나타났다.
이러한 결과는 ViT가 self-attention을 통해 이미지의 전역적 정보를 실제로 활용하고 있음을 보여준다. 동시에 일부 attention head는 지역적 정보를 처리하며, 이는 CNN의 초기 convolution layer와 유사한 역할을 할 수 있다. 따라서 ViT는 CNN처럼 명시적인 inductive bias를 강하게 가지지는 않지만, 대규모 학습을 통해 이미지의 위치 구조와 의미적으로 중요한 영역을 스스로 학습할 수 있음을 확인할 수 있다.
4.6 SELF-SUPERVISION
Transformer는 자연어처리 task에서 인상적인 성능을 보여주었다. 하지만 Transformer의 성공은 뛰어난 확장성 때문만이 아니라, 대규모 self-supervised pre-training, 즉 자기지도 사전학습 덕분이기도 하다. BERT에서 사용한 masked language modeling 방식을 모방하여, ViT에 대해 masked patch prediction을 사용한 자기지도학습을 예비적으로 실험했다. Self-supervised pre-training을 사용했을 때, 더 작은 모델인 ViT-B/16은 ImageNet에서 79.9% accuracy를 달성했다. 이는 처음부터 학습한 경우보다 약 2% 향상된 결과이다. 하지만 supervised pre-training과 비교하면 여전히 약 4% 낮은 성능을 보였다. 자세한 내용은 Appendix B.1.2에 제시하고, contrastive pre-training 같은 다른 자기지도학습 방식은 향후 연구로 남겨두었다.
5 CONCLUSION
Transformer를 이미지 인식에 직접 적용하는 방법을 탐구했다. 기존 컴퓨터 비전 연구들이 self-attention을 사용할 때 이미지에 특화된 inductive bias를 구조에 넣었던 것과 달리, 이 논문은 초기 patch extraction 단계를 제외하고는 이미지에 특화된 inductive bias를 거의 넣지 않았다. 대신 이미지를 여러 개의 patch sequence로 해석하고, 이를 NLP에서 사용되는 표준 Transformer encoder로 처리했다. 이 단순하지만 확장 가능한 전략은 대규모 데이터셋에서 사전학습했을 때 놀라울 정도로 잘 작동했다.
그 결과 Vision Transformer는 여러 이미지 분류 데이터셋에서 기존 state-of-the-art 모델과 비슷하거나 더 좋은 성능을 달성했다.
또한 사전학습 비용도 상대적으로 낮았다. 하지만 이러한 초기 결과가 긍정적이기는 해도, 아직 해결해야 할 과제도 많이 남아 있다.
첫 번째 과제는 ViT를 object detection이나 segmentation 같은 다른 컴퓨터 비전 task에 적용하는 것이다. 저자들의 결과와 DETR 연구 결과를 함께 보면, 이런 방향은 가능성이 있어 보인다. 두 번째 과제는 self-supervised pre-training 방법을 더 탐구하는 것이다. 초기 실험에서는 self-supervised pre-training이 성능을 향상시키는 것을 확인했지만, 여전히 대규모 supervised pre-training과는 큰 차이가 있었다. 마지막으로, ViT를 더 크게 확장하면 성능이 더 향상될 가능성이 있다고 설명한다.