https://arxiv.org/abs/1506.02640
You Only Look Once: Unified, Real-Time Object Detection
We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabili
arxiv.org
Abstract
YOLO는 새로운 객체 탐지(object detection) 방법이다. 기존 객체 탐지 방법들은 classifier를 객체 탐지에 재사용하는 방식을 사용하였다. 반면 YOLO는 객체 탐지를 bounding box와 class probability를 예측하는 하나의 regression 문제로 정의하였다. 단일 neural network가 이미지 전체를 한 번만 보고 bounding box와 class probability를 직접 예측한다. 전체 detection pipeline이 하나의 network로 구성되어 있기 때문에 detection 성능 자체를 end-to-end 방식으로 최적화할 수 있다.
YOLO의 unified architecture는 매우 빠르다. 기본 YOLO 모델은 초당 45프레임(FPS)으로 실시간 처리가 가능하며, 더 작은 모델인 Fast YOLO는 155FPS를 달성하였다. 또한 기존 real-time detector보다 약 2배 높은 mAP를 기록하였다. YOLO는 state-of-the-art detector보다 localization error는 다소 많지만 background false positive는 훨씬 적었다. 또한 YOLO는 객체에 대한 일반화된 표현을 학습하며, artwork 같은 새로운 도메인에서도 DPM이나 R-CNN보다 더 좋은 성능을 보였다.

Figure 1은 YOLO의 전체 detection pipeline을 보여준다. 입력 이미지를 448×448로 resize한 뒤 단일 convolutional network를 통과시키고 bounding box와 confidence score를 예측한다. 이후 thresholding과 non-max suppression을 통해 최종 detection 결과를 생성한다.
1. Introduction
인간은 이미지를 보는 즉시 어떤 객체가 어디에 있는지 빠르게 이해할 수 있다. 이러한 능력은 자율주행, 보조 기기, 로봇 시스템 등 다양한 분야에서 중요하다. 하지만 기존 객체 탐지 시스템들은 매우 복잡한 구조를 사용하였다. 기존 detector들은 일반적으로 classifier를 여러 위치와 크기에서 반복 수행하는 방식을 사용하였다. DPM은 sliding window 기반 방식을 사용하였고, R-CNN은 먼저 region proposal을 생성한 뒤 CNN classifier를 수행하였다. 이후 bounding box refinement, duplicate removal 등 추가적인 후처리 과정도 필요하였다. 이러한 pipeline 구조는 속도가 느리고 각 단계가 분리되어 있기 때문에 최적화가 어렵다.
YOLO는 객체 탐지를 하나의 regression 문제로 정의하였다. 이미지 픽셀에서 bounding box 좌표와 class probability를 직접 예측하며, 이미지 전체를 단 한 번만 보고 detection을 수행한다. 즉, region proposal 과정을 제거하고 단일 convolutional network만으로 detection을 수행한다. YOLO의 첫 번째 장점은 매우 빠르다는 점이다. detection을 regression 문제로 정의하였기 때문에 복잡한 pipeline이 필요하지 않다. 기본 YOLO는 45FPS로 동작하며 Fast YOLO는 150FPS 이상을 달성하였다. 이는 streaming video를 실시간으로 처리할 수 있는 수준이다.
두 번째 장점은 이미지 전체 문맥(global context)을 함께 학습할 수 있다는 점이다. 기존 sliding window 방식이나 region proposal 기반 방법들은 이미지 일부만 보기 때문에 background를 객체로 잘못 인식하는 경우가 많았다. 반면 YOLO는 전체 이미지를 동시에 보기 때문에 background error가 훨씬 적었다. 세 번째 장점은 일반화 성능이다. YOLO는 자연 이미지뿐 아니라 artwork와 같은 새로운 도메인에서도 높은 성능을 보였다. 이는 객체의 형태(shape)와 관계를 함께 학습하기 때문이다. 하지만 YOLO는 localization accuracy 측면에서는 기존 state-of-the-art detector보다 다소 부족하였다. 특히 작은 객체 탐지에서 약점을 보였다. 논문에서는 이후 실험에서 이러한 trade-off를 자세히 분석한다.
2. Unified Detection
YOLO는 객체 탐지의 모든 과정을 하나의 neural network로 통합하였다. 네트워크는 이미지 전체를 입력으로 받아 bounding box와 class probability를 동시에 예측한다. 따라서 전체 이미지와 객체 간 관계를 함께 고려할 수 있으며 end-to-end 학습이 가능하다. YOLO는 입력 이미지를 S×S grid로 나눈다. 객체 중심이 특정 grid cell 안에 존재하면 해당 grid cell이 그 객체를 담당한다. 각 grid cell은 B개의 bounding box와 confidence score를 예측한다. confidence score는 객체 존재 여부와 localization accuracy를 함께 반영하며 다음과 같이 정의된다.
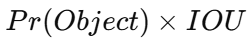
객체가 존재하지 않는 경우 confidence는 0이 되고, 객체가 존재하는 경우에는 예측 bounding box와 ground truth 사이의 IOU를 의미한다. 각 bounding box는 x, y, w, h, confidence 총 5개의 값을 가진다. x,y는 bounding box 중심 좌표이며, w,h는 width와 height를 의미한다. 또한 각 grid cell은 conditional class probability Pr(Classi∣Object)도 함께 예측한다. 테스트 시에는 conditional class probability와 confidence score를 곱하여 최종 class-specific confidence score를 계산한다.
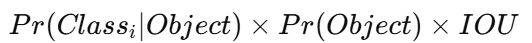
이를 통해 객체 종류와 localization accuracy를 동시에 반영할 수 있다. 논문에서는 PASCAL VOC 기준으로 S=7, B=2, C=20을 사용하였다. 따라서 최종 출력 tensor는 다음과 같다. -> 7×7×30
즉, 각 grid cell은 bounding box 2개와 class probability 20개를 예측한다.
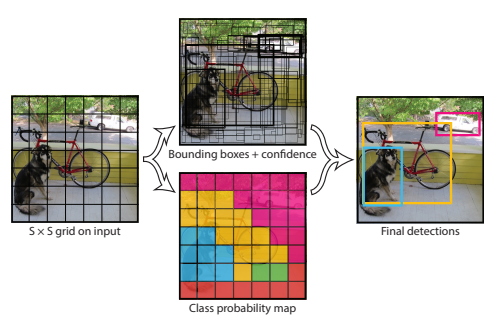
Figure 2는 YOLO의 전체 모델 구조를 보여준다. 입력 이미지를 S×S grid로 나눈 뒤 각 grid cell이 bounding box와 confidence score, class probability를 예측한다. 최종적으로 이 값들을 결합하여 detection 결과를 생성한다.
2.1 Network Design
YOLO는 convolutional neural network 기반 구조를 사용한다. 초기 convolution layer들은 이미지 특징(feature)을 추출하고 이후 fully connected layer가 bounding box와 class probability를 예측한다. 네트워크 구조는 GoogLeNet의 영향을 받았으며 총 24개의 convolution layer와 2개의 fully connected layer로 구성된다. GoogLeNet의 inception module 대신 1×1 convolution과 3×3 convolution을 반복적으로 사용하는 구조를 사용하였다. 1×1 convolution은 feature dimension reduction 역할을 수행하여 연산량 감소에 도움을 준다. 또한 논문에서는 더 빠른 detection을 위한 Fast YOLO도 함께 제안하였다. Fast YOLO는 convolution layer 수를 줄이고 filter 수도 감소시킨 구조이다. 정확도는 다소 낮지만 훨씬 빠른 속도를 가진다.
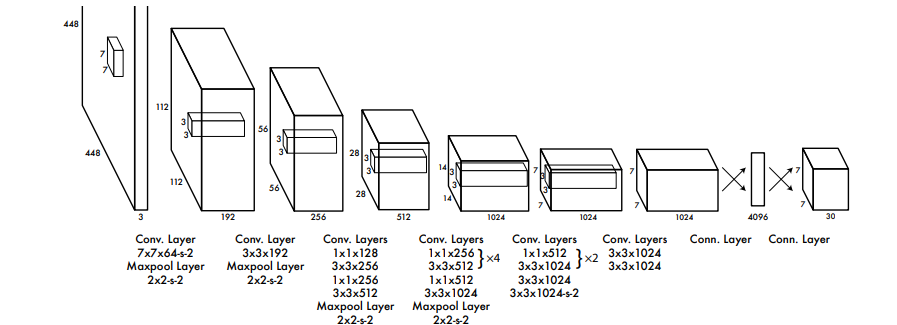
Figure 3은 YOLO의 전체 network architecture를 보여준다. 입력 이미지는 448×448×3 크기로 들어가며, 총 24개의 convolution layer와 2개의 fully connected layer로 구성된다. 1×1 convolution layer를 사용하여 feature dimension을 줄인 뒤 3×3 convolution을 수행하는 구조를 반복적으로 사용한다. 또한 detection task 이전에는 ImageNet classification task로 convolution layer를 pretraining하며, 이후 입력 해상도를 224×224에서 448×448로 증가시켜 detection에 맞게 fine-tuning한다.
2.2 Training
YOLO는 먼저 ImageNet 1000-class classification dataset으로 convolution layer를 pretraining한다. Figure 3의 처음 20개 convolution layer 뒤에 average pooling layer와 fully connected layer를 추가하여 classification task를 학습하였다. 약 일주일 동안 학습을 진행하였으며, ImageNet 2012 validation set에서 top-5 accuracy 88%를 달성하였다. 이후 detection task를 위해 network 구조를 수정한다.
Detection task에서는 pretrained network 뒤에 추가적인 convolution layer와 fully connected layer를 붙인다. 또한 detection은 더 세밀한 spatial information이 필요하기 때문에 입력 해상도를 224×224에서 448×448로 증가시켰다. YOLO의 최종 output layer는 bounding box coordinate와 class probability를 함께 예측한다. bounding box의 width와 height는 이미지 전체 크기에 대해 normalize되며, x,y 좌표는 특정 grid cell 내부에서의 offset 형태로 표현된다. 따라서 모든 값은 0~1 사이 범위를 가지게 된다. Activation function으로는 마지막 layer에서 linear activation을 사용하고, 나머지 layer에서는 Leaky ReLU를 사용한다.
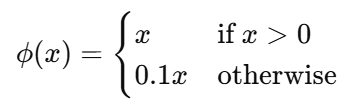
즉 음수 영역에서도 gradient가 완전히 0이 되지 않도록 설계하였다. YOLO는 전체 모델 학습에 sum-squared error loss를 사용한다. 하지만 detection 문제에서는 classification error와 localization error를 동일하게 취급하는 문제가 존재한다. 또한 대부분의 grid cell에는 객체가 존재하지 않기 때문에 no-object confidence loss가 지나치게 커지는 문제가 발생한다. 이 경우 객체가 존재하는 cell의 gradient보다 no-object cell의 gradient가 훨씬 커져 학습이 불안정해질 수 있다.
-> 이를 해결하기 위해 두 개의 hyperparameter 사용 : 람다_coord=5, 람다_noobj=0.5
-> bounding box coordinate loss의 비중은 증가시키고, 객체가 없는 cell의 confidence loss는 감소시킨다.
-> 또한 큰 bounding box와 작은 bounding box의 오차를 동일하게 취급하지 않기 위해 width와 height 자체가 아니라 square root 값을 예측한다. (루트 w, 루트 h)
이를 통해 작은 객체 localization에 더 민감하게 반응할 수 있다. YOLO는 하나의 grid cell에서 여러 bounding box를 예측하지만 학습 시에는 하나의 predictor만 특정 객체를 담당하도록 한다. Ground truth box와 가장 높은 IOU를 가진 predictor가 해당 객체를 “responsible”하게 된다. 이를 통해 predictor specialization이 가능해지며 특정 predictor가 특정 크기나 aspect ratio의 객체를 더 잘 학습할 수 있게 된다. 논문에서 사용한 전체 loss function은 다음과 같다.

여기서 1ijobj는 j번째 bounding box predictor가 해당 객체를 담당하는 경우를 의미한다. 또한 classification loss는 객체가 존재하는 grid cell에 대해서만 계산된다.
2.3 Inference
YOLO는 test time에서도 단 한 번의 network evaluation만 수행한다. 기존 classifier 기반 detector처럼 region proposal을 반복적으로 생성하거나 여러 번의 classification 과정을 수행할 필요가 없다. PASCAL VOC 기준으로 YOLO는 이미지당 98개의 bounding box와 각 bounding box에 대한 class probability를 예측한다. 이러한 구조 덕분에 YOLO는 매우 빠른 detection 속도를 가진다. YOLO의 grid 기반 구조는 bounding box prediction에 spatial diversity를 부여한다. 일반적으로 객체가 어느 grid cell에 속하는지가 명확하기 때문에 하나의 객체에 대해 하나의 bounding box만 예측되는 경우가 많다. 하지만 큰 객체이거나 여러 grid cell 경계에 걸친 객체는 여러 cell에서 동시에 detection될 수 있다. 이를 해결하기 위해 YOLO는 non-max suppression(NMS)을 사용한다. R-CNN이나 DPM처럼 heavily dependent한 것은 아니지만, NMS를 적용하면 약 2~3%의 mAP 향상을 얻을 수 있었다. 즉 YOLO는 기본적으로 중복 detection이 비교적 적지만, 추가적인 post-processing을 통해 detection 성능을 더 향상시킬 수 있다.
2.4 Limitations of YOLO
YOLO는 매우 빠르고 단순한 구조를 가지지만 몇 가지 한계도 존재한다. 가장 큰 문제는 grid 기반 구조에서 발생하는 strong spatial constraint이다. 각 grid cell은 제한된 개수의 bounding box만 예측할 수 있으며 하나의 class만 담당할 수 있다. 따라서 서로 가까이 붙어 있는 여러 객체를 동시에 detection하는 데 어려움이 있다. 특히 새 떼(flocks of birds)처럼 작은 객체가 밀집된 경우 detection 성능이 크게 감소한다. 또한 YOLO는 bounding box를 데이터 기반으로 직접 학습하기 때문에 학습 데이터에서 자주 등장하지 않는 새로운 aspect ratio나 unusual configuration에 일반화하기 어렵다. 즉 객체의 형태나 배치가 기존 데이터와 크게 다른 경우 localization accuracy가 감소할 수 있다.
YOLO는 여러 번의 downsampling layer를 사용하기 때문에 bounding box prediction에 필요한 fine-grained feature를 잃어버리는 문제도 존재한다. 따라서 작은 객체 localization에서 약점을 보인다.
또 다른 문제는 loss function 자체이다. YOLO의 loss function은 큰 bounding box와 작은 bounding box의 error를 동일하게 처리한다. 하지만 실제 detection에서는 작은 bounding box의 작은 오차가 IOU에 훨씬 큰 영향을 준다. 따라서 작은 객체 detection에서 localization error가 더 크게 나타난다. 논문은 YOLO의 주요 error source가 localization error라고 분석하였다. 즉 YOLO는 객체 존재 자체는 잘 예측하지만 bounding box 위치를 정확하게 맞추는 데는 기존 state-of-the-art detector보다 부족한 성능을 보였다.
3. Comparison to Other Detection Systems
객체 탐지는 컴퓨터 비전 분야의 핵심 문제 중 하나이며, 기존 detector들은 일반적으로 robust feature extraction 이후 classifier 또는 localizer를 사용하는 구조를 가진다. 이러한 classifier들은 sliding window 방식으로 이미지 전체에 적용되거나, region proposal을 기반으로 특정 영역에만 적용된다. 논문에서는 YOLO를 기존 주요 detection framework들과 비교하며 구조적 차이와 장단점을 설명한다.
Deformable Parts Model (DPM)
DPM은 sliding window 기반 detector이다. 먼저 HOG(Histogram of Oriented Gradients)와 같은 handcrafted feature를 추출한 뒤 classifier를 사용하여 객체를 탐지한다. 또한 high-scoring region에 대해 bounding box prediction과 refinement를 수행한다. 즉 feature extraction, classification, localization 등이 각각 분리된 pipeline 형태로 구성된다. 반면 YOLO는 이러한 모든 과정을 단일 convolutional neural network 하나로 통합하였다. Feature extraction, bounding box prediction, contextual reasoning 등을 동시에 수행하며 detection task 자체에 맞게 feature를 end-to-end 방식으로 학습한다. 따라서 DPM보다 훨씬 빠르고 정확한 detection이 가능하다.
R-CNN
R-CNN 계열 모델은 sliding window 대신 region proposal을 사용한다. 먼저 Selective Search를 이용하여 potential bounding box를 생성하고, 이후 CNN으로 feature extraction을 수행한다. 이후 SVM classifier로 classification을 수행하고 linear regression으로 bounding box를 refinement한 뒤 non-max suppression을 적용한다. 하지만 이러한 구조는 매우 복잡하다. 각 단계가 독립적으로 존재하기 때문에 각각 따로 학습해야 하며 속도도 매우 느리다. 논문에서는 당시 R-CNN이 test time에서 이미지 한 장당 40초 이상이 걸린다고 설명한다. YOLO 역시 grid cell이 bounding box를 예측한다는 점에서는 R-CNN과 유사하지만 중요한 차이가 존재한다. YOLO는 spatial constraint를 사용하기 때문에 동일 객체에 대한 duplicate detection이 상대적으로 적다. 또한 R-CNN은 약 2000개의 proposal을 생성하지만 YOLO는 단 98개의 bounding box만 예측한다. 가장 큰 차이는 YOLO가 모든 과정을 단일 network 안에서 jointly optimized한다는 점이다.
Other Fast Detectors
Fast R-CNN과 Faster R-CNN은 기존 R-CNN의 속도를 개선하기 위해 제안된 모델들이다. Fast R-CNN은 convolution computation을 공유하여 classification 속도를 높였고, Faster R-CNN은 region proposal 자체를 neural network로 대체하였다.
하지만 두 모델 모두 여전히 real-time performance에는 도달하지 못하였다. Faster R-CNN은 proposal generation 속도를 크게 개선하였지만 여전히 YOLO보다 훨씬 느렸다. 논문은 YOLO가 “fast by design” 구조라는 점을 강조한다. 즉 기존 pipeline 일부를 최적화한 것이 아니라 아예 pipeline 자체를 제거한 것이다. 기존 DPM 계열 detector들도 GPU acceleration, cascade, fast HOG computation 등을 사용하여 속도를 개선하려 하였다. 하지만 대부분 real-time performance를 달성하지 못하였다.
Deep MultiBox
Deep MultiBox는 Selective Search 대신 convolutional neural network를 사용하여 region proposal을 생성하는 모델이다. Bounding box prediction을 neural network로 수행한다는 점에서 YOLO와 유사하다. 하지만 MultiBox는 general object detection system이 아니라 proposal generation 단계에 가까우며, 이후 추가적인 classifier가 필요하다. 반면 YOLO는 bounding box prediction과 class probability prediction을 모두 수행하는 complete detection system이다. 즉 별도의 classifier나 proposal refinement 과정이 필요하지 않다.
OverFeat
OverFeat는 convolutional neural network를 사용하여 localization과 detection을 동시에 수행하는 모델이다. Sliding window detection을 CNN 기반으로 효율적으로 구현하였지만 여전히 localization 중심 구조이며 global context reasoning이 부족하다. 따라서 coherent detection을 위해 추가적인 post-processing이 필요하다. 반면 YOLO는 이미지 전체를 동시에 보기 때문에 객체 간 관계와 global context를 함께 학습할 수 있다. 이는 YOLO가 background false positive를 줄일 수 있었던 중요한 이유 중 하나이다.
MultiGrasp
YOLO의 grid 기반 bounding box prediction 방식은 이전의 MultiGrasp system과 유사하다. MultiGrasp는 grasp detection을 regression 문제로 정의하여 robotic grasping task를 수행하였다. 하지만 grasp detection은 단일 객체에 대한 graspable region만 찾으면 되는 비교적 단순한 문제이다. 반면 YOLO는 여러 객체에 대해 bounding box와 class probability를 동시에 예측해야 한다. 즉 훨씬 복잡한 general object detection 문제를 해결한다는 점에서 차이가 있다.
4. Experiments
논문에서는 먼저 YOLO를 기존 real-time detector들과 비교하여 속도와 정확도를 분석하였다. 이후 YOLO와 Fast R-CNN의 error 유형을 비교하고, YOLO를 Fast R-CNN과 결합했을 때의 성능 변화도 함께 분석한다. 또한 VOC 2012 benchmark와 artwork dataset에서도 실험을 수행하여 YOLO의 일반화 성능을 평가하였다.
4.1 Comparison to Other Real-Time Systems
객체 탐지 분야에서는 기존 detection pipeline의 속도를 개선하려는 연구들이 많이 존재하였다. 하지만 대부분은 일부 component만 최적화한 수준이었으며, 실제 real-time performance(30FPS 이상)를 달성한 경우는 거의 없었다. 논문에서는 YOLO를 기존 fast detector들과 비교하여 accuracy-speed tradeoff를 분석하였다.

Table 1은 다양한 detector들의 mAP와 FPS를 비교한 결과이다. Fast YOLO는 155FPS로 가장 빠른 detector였으며, 52.7% mAP를 기록하였다. 기본 YOLO는 45FPS와 63.4% mAP를 기록하여 real-time performance를 유지하면서도 높은 정확도를 달성하였다. 반면 기존 detector들은 정확도는 높았지만 속도가 매우 느렸다. Fast R-CNN은 70.0% mAP를 기록하였지만 0.5FPS에 불과하였다. Faster R-CNN 역시 Faster proposal generation을 사용하였지만 YOLO보다 훨씬 느렸다. Faster R-CNN VGG-16은 73.2% mAP를 기록하였지만 속도는 7FPS였다.
논문은 YOLO가 “fast by design” 구조라는 점을 강조한다. 기존 detector들은 region proposal, feature extraction, classification 등의 pipeline 일부를 최적화하는 방식이었다. 반면 YOLO는 처음부터 detection 자체를 하나의 regression 문제로 정의하여 pipeline 자체를 제거하였다. 또한 YOLO VGG-16 모델도 실험하였다. 이 모델은 정확도는 증가하였지만 속도가 크게 감소하였다. 따라서 이후 real-time performance를 유지하는 기본 YOLO와 Fast YOLO 중심으로 실험을 진행한다. 실험 결과 YOLO는 기존 detector 대비 localization accuracy는 다소 낮았지만, real-time object detection이라는 측면에서는 매우 큰 성과를 보였다. 특히 Fast YOLO는 기존 real-time detector보다 약 2배 이상 높은 mAP를 기록하였다.
4.2 VOC 2007 Error Analysis
논문에서는 YOLO와 Fast R-CNN의 차이를 더 자세히 분석하기 위해 VOC 2007 benchmark에서 error analysis를 수행하였다. 특히 detection error를 유형별로 나누어 비교하였다. Fast R-CNN은 당시 PASCAL VOC에서 가장 높은 성능을 보이던 detector 중 하나였기 때문에 비교 대상으로 사용되었다.
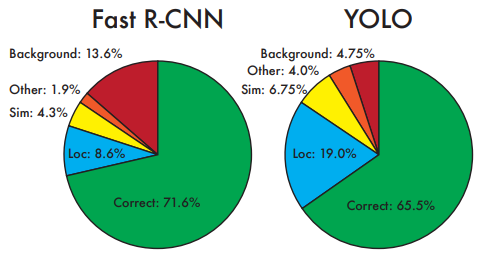
Figure 4는 YOLO와 Fast R-CNN의 error distribution을 비교한 결과이다. YOLO는 localization error 비중이 매우 높았으며, 이는 YOLO의 주요 문제점이 bounding box localization accuracy라는 것을 보여준다. 반면 Fast R-CNN은 background false positive 비율이 매우 높았다. YOLO는 객체 존재 자체는 잘 판단하지만 bounding box 위치를 정확히 맞추는 데 약점이 있었고, Fast R-CNN은 localization accuracy는 높지만 background false positive가 많았다. 이러한 차이는 이후 YOLO와 Fast R-CNN을 결합했을 때 성능 향상으로 이어진다.
4.3. Combining Fast R-CNN and YOLO
앞선 error analysis에서 YOLO는 background false positive가 적고, Fast R-CNN은 localization accuracy가 높다는 차이를 확인하였다. 논문에서는 이러한 특성을 활용하여 YOLO와 Fast R-CNN을 결합하는 실험을 수행하였다. YOLO가 특정 객체를 높은 confidence로 예측한 경우, 해당 Fast R-CNN detection의 score를 증가시키는 방식이다. 즉 YOLO를 이용해 Fast R-CNN의 background false positive를 줄인다.

Table 2는 YOLO와 Fast R-CNN 결합 결과를 보여준다. 기존 Fast R-CNN은 71.8% mAP를 기록했지만, YOLO와 결합했을 때 75.0%까지 향상되었다. 이는 두 모델이 서로 다른 종류의 error를 가지기 때문이다. YOLO는 localization error는 많지만 background error가 적고, Fast R-CNN은 localization accuracy는 높지만 background false positive가 많다. 따라서 두 모델을 결합하면 서로의 약점을 보완할 수 있었다.
4.4. VOC 2012 Results
논문에서는 YOLO를 PASCAL VOC 2012 benchmark에서도 평가하였다. YOLO는 VOC 2012 test set에서 57.9% mAP를 기록하였다. 이는 당시 최고 성능 detector보다는 낮았지만, real-time detector 중에서는 매우 높은 성능이었다.

YOLO는 bottle, sheep, tv/monitor 같은 작은 객체 category에서 낮은 성능을 보였다. 이는 grid 기반 구조와 localization limitation 때문이다. 반면 cat, train 같은 category에서는 높은 성능을 기록하였다. 또한 Fast R-CNN과 YOLO를 결합한 모델은 VOC 2012 leaderboard에서 높은 성능을 기록하였다. 논문은 이를 통해 YOLO가 단독 detector뿐 아니라 다른 detector와 결합했을 때도 효과적이라는 점을 보여준다.
4.5. Generalizability: Person Detection in Artwork
논문에서는 detector들의 일반화 성능을 평가하기 위해 artwork dataset에서 person detection 실험을 수행하였다. 실험에는 Picasso Dataset과 People-Art Dataset이 사용되었다.
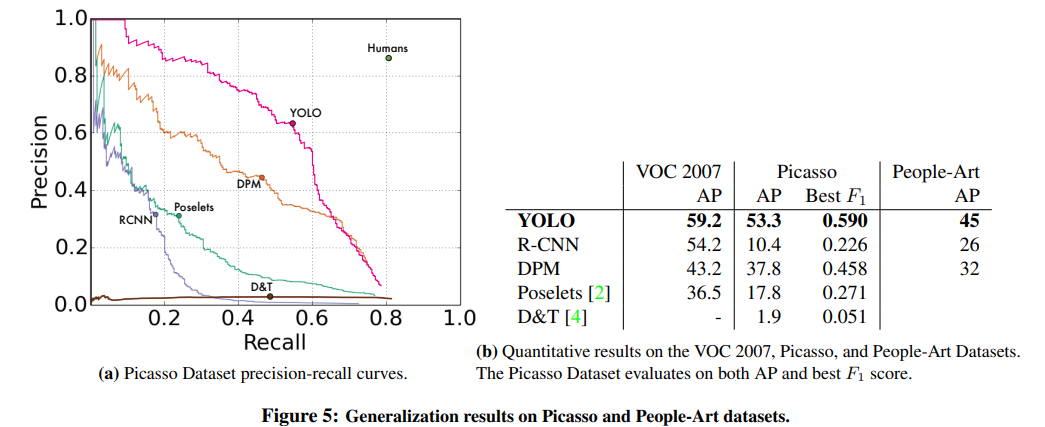
Figure 5는 YOLO와 기존 detector들의 일반화 성능을 비교한 결과이다. R-CNN은 artwork dataset에서 성능이 크게 감소하였지만, YOLO는 비교적 높은 성능을 유지하였다. 이는 YOLO가 이미지 전체 문맥과 객체 구조를 함께 학습하기 때문이다. 반면 DPM은 artwork에서도 비교적 안정적인 성능을 보였지만 전체 detection 성능은 YOLO보다 낮았다. 논문은 이를 통해 YOLO가 새로운 domain에서도 잘 일반화된다고 설명한다.

5. Real-Time Detection In The Wild
논문에서는 YOLO를 webcam 환경에 적용하여 real-time detection 성능을 확인하였다. YOLO는 streaming video에서도 매우 빠르게 동작하였으며, 실시간으로 객체를 detection하고 tracking하는 것이 가능하였다. 기존 detector들은 detection 속도가 매우 느려 실시간 환경에서 사용하기 어려웠다. 반면 YOLO는 단일 neural network만 사용하기 때문에 low latency를 가지며, background prediction error도 적었다. 따라서 실제 환경에서도 안정적으로 detection을 수행할 수 있었다.
6. Conclusion
본 논문에서는 객체 탐지를 하나의 regression 문제로 정의한 YOLO를 제안하였다. YOLO는 region proposal 기반의 복잡한 detection pipeline을 제거하고, 단일 convolutional neural network만으로 bounding box와 class probability를 동시에 예측한다.
YOLO의 가장 큰 특징은 매우 빠른 속도이다. 기본 YOLO는 45FPS, Fast YOLO는 155FPS를 달성하여 real-time object detection이 가능하였다. 또한 background false positive가 적고 새로운 domain에서도 높은 일반화 성능을 보였다.
반면 localization accuracy 측면에서는 기존 state-of-the-art detector보다 다소 부족하였으며, 특히 작은 객체 탐지에서 약점을 보였다. 하지만 YOLO는 detection을 end-to-end 방식으로 최적화할 수 있다는 점에서 매우 중요한 의미를 가진다. YOLO가 object detection 분야의 새로운 방향성을 제시하였다. 이후 YOLOv2, YOLOv3, YOLOv4 등 다양한 후속 연구의 기반이 되었으며, real-time object detection 분야에 큰 영향을 주었다.