https://arxiv.org/abs/1406.4729
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
Existing deep convolutional neural networks (CNNs) require a fixed-size (e.g., 224x224) input image. This requirement is "artificial" and may reduce the recognition accuracy for the images or sub-images of an arbitrary size/scale. In this work, we equip th
arxiv.org
Abstract
기존의 CNN은 고정된 크기 (ex:224x224)의 입력 이미지를 필요로 한다. 하지만 이 요구사항은 다양한 크기나 비율을 가진 이미지 또는 부분 이미지(sub-image)에 대해 인식 정확도를 떨어뜨릴 수 있다. 이러한 문제를 해결하기 위해 Spatial Pyramid Pooling(SPP) 이라는 새로운 pooling 전략을 CNN에 적용하였다. 제안된 네트워크 구조인 SPP-net 은 입력 이미지의 크기나 스케일(scale)에 관계없이 항상 고정 길이의 특징 벡터(feature representation)를 생성할 수 있다. 또한 pyramid pooling은 객체의 형태 변형(object deformation)에 대해서도 강인한 특성을 가진다. 이러한 장점 덕분에 SPP-net은 전반적으로 CNN 기반 이미지 분류 성능을 향상시킬 수 있다.
ImageNet 2012 데이터셋 실험 결과, 서로 다른 구조를 가진 다양한 CNN 아키텍처에서 모두 정확도를 향상시키는 것을 확인하였다. 또한 Pascal VOC 2007과 Caltech101 데이터셋에서는 fine-tuning 없이도 단일 full-image representation만 사용하여 당시 최고 수준(state-of-the-art)의 분류 성능을 달성하였다. SPP-net의 강점은 객체 탐지(object detection)에서도 크게 나타난다. 기존 방식은 후보 영역(region proposal)마다 convolution 연산을 반복 수행해야 했지만, SPP-net은 전체 이미지에 대해 convolution feature map을 한 번만 계산한 뒤, 원하는 영역에 대해서만 pooling을 수행하여 고정 길이 특징 벡터를 생성한다. 이를 통해 불필요한 convolution 계산을 제거하였다. 그리하여 기존 R-CNN보다 약 24배 ~102배 더 빠르다.
-> 기존 CNN은 고정 입력 크기 요구해 crop이나 wrap 과정 필요했는데 SPP는 입력 크기 상관 없이 고정 길이 feature vector 생성할 수 있어 다양한 scale과 spatial 정보를 유지할 수 있다.
1. Introduction
최근 컴퓨터 비전 분야에서는 딥 컨볼루션 신경망(CNN)의 발전과 대규모 학습 데이터셋의 등장으로 인해 매우 큰 변화가 일어나고 있다. CNN 기반 방법들은 이미지 분류(image classification), 객체 탐지(object detection), 다양한 인식(recognition) 작업뿐 아니라 비인식(non-recognition) 작업에서도 기존 최고 성능(state-of-the-art)을 크게 향상시키고 있다. 하지만 CNN의 학습과 테스트 과정에는 한 가지 기술적인 문제가 존재한다. 대부분의 CNN은 224×224처럼 고정된 크기의 입력 이미지를 필요로 한다는 점이다. 현재 일반적으로 사용하는 방법은 입력 이미지를 crop하거나 warp(이미지 강제로 늘리거나 줄이기)하여 강제로 맞추는 것이다. crop 방식은 객체 전체가 포함되지 않을 수 있고, warp 방식은 이미지 형태가 왜곡될 수 있다. 따라서 이미지 내용 손실(content loss)이나 기하학적 왜곡(geometric distortion)이 발생하여 인식 정확도가 떨어질 수 있다. 또한 객체 크기가 다양한 경우, 하나의 고정된 입력 크기만 사용하는 것은 적절하지 않을 수 있다.
Convolution layer는 sliding window 방식으로 동작하기 때문에 입력 이미지 크기가 달라도 feature map을 생성할 수 있다. 즉 convolution layer 자체는 고정 입력 크기를 요구하지 않는다. 반면 fully connected layer는 고정 길이의 벡터만 입력으로 받을 수 있기 때문에, 네트워크 전체가 고정 크기 입력만 받도록 제한된다. 즉 fixed-size constraint는 fully connected layer 때문에 발생하는 것이다. 이를 해결하기 위해 논문은 마지막 convolution layer 위에 Spatial Pyramid Pooling(SPP) layer를 추가한다. SPP layer는 입력 이미지 크기와 관계없이 항상 고정 길이 출력(feature vector)을 생성할 수 있다. 생성된 고정 길이 벡터는 이후 fully connected layer에 입력된다. 즉 논문은 이미지 입력 단계에서 crop이나 warp를 수행하는 대신, convolution feature map 이후 단계에서 정보를 aggregation(통합)하여 입력 크기 제한 문제를 해결하였다. 논문에서는 이러한 새로운 구조를 SPP-net 이라고 부른다.

Spatial Pyramid Pooling(SPP)은 기존 Bag-of-Words(BoW) 모델을 확장한 방법으로, 컴퓨터 비전 분야에서 매우 성공적으로 사용되어 왔다. SPP는 이미지를 여러 단계(level)의 spatial bin으로 나누고, 각 영역의 local feature를 pooling한다. SPP는 CNN에 적용했을 때 3가지 장점을 가진다.
1. 입력 이미지 크기와 관계없이 fixed-length output 생성 가능
2. single-level pooling이 아니라 multi-level pooling 사용
3. 다양한 scale에서 추출된 feature를 pooling 가능
특히 multi-level pooling은 object deformation(객체 형태 변화)에 강인한 특성을 가진다고 알려져 있다. 또한 SPP-net은 테스트 단계뿐 아니라 학습 단계에서도 다양한 크기의 입력 이미지를 사용할 수 있게 한다. 논문에서는 multi-size training을 제안한다.
1. 방법 : 서로 다른 입력 크기의 net 사용 -> 모든 parameters 공유 -> epoch마다 입력 크기 변경하며 학습
2. 예시 : 한 epoch는 224x224, 다음 epoch는 180x180
이러한 방식은 scale invariance를 증가시키고 overfitting을 감소시키는 효과를 가진다. 논문에서는 multi-size training이 기존 single-size training과 비슷한 속도로 수렴하면서도 더 좋은 성능을 보였다고 설명한다. 논문은 SPP의 장점이 특정 CNN 구조에만 적용되는 것이 아니라고 한다. SPP-net은 object detection에서도 큰 장점을 가진다. 기존 R-CNN은 약 2,000개의 candidate window 각각에 CNN을 반복 수행해야 했기 때문에 feature extraction 시간이 매우 오래 걸렸다. 반면 SPP-net은 전체 이미지에 대해 conv feature map을 한번만 계산하고 feature map의 원하는 영역에서 pooling을 수행하는 방식을 사용한다. conv 연산을 반복하지 않고 feature map을 재사용할 수 있기 때문에 계산량이 크게 감소한다.
* spatial arrangement : feature의 공간적 위치 정보 (ex : edge가 어디 위치하는지, 객체가 이미지 어느 부분에 있는지)
* Bag-of-words : 이미지를 local feature들의 집합처럼 표현하는 전통적 computer vision 방법 -> spactial imformation 보존 불가
* Scale Invariance : 객체 크기가 달라져도 비슷하게 인식할 수 있는 능력 (ex : 가까운 자동차, 먼 자동차 둘 다 같은 객체로 인식)
* Candidate Window : 객체가 존재할 가능성이 있는 후보 영역 -> object detection에서 사용
2 DEEP NETWORKS WITH SPATIAL PYRAMID POOLING
2.1 Convolutional Layers and Feature Maps
대표적으로 많이 사용되는 7-layer CNN 구조를 기준으로, 처음 5개 layer는 convolution layer이고 일부 뒤에는 pooling layer가 따라온다. 마지막 2개 layer는 fully connected layer이며, 마지막에는 N-way softmax classifier가 존재한다. 여기서 N은 클래스(category)의 개수를 의미한다. Convolution layer는 입력 이미지 크기에 상관없이 동작할 수 있다. Convolution filter는 sliding window 방식으로 이미지를 이동하며 연산을 수행하고, 결과로 feature map을 생성한다. 생성된 feature map은 입력 이미지의 spatial information(공간 정보)을 유지한다. 즉 feature response의 강도뿐 아니라 위치 정보까지 함께 포함하고 있다.

Figure 2는 conv5 layer의 일부 filter들이 어떤 패턴에 반응하는지를 보여주는 그림이다. 특정 filter들이 특정 semantic pattern을 학습한다. 예를들어 55번 필터는 원 모양에 강하게 반응하고 66번째 필터는 ^ 형태에 반응한다.
-> CNN의 convolution layer는 단순 edge 수준 특징만 학습하는 것이 아니라, 점점 더 의미 있는 시각 패턴(semantic content)을 학습한다는 것을 보여준다.
화살표는 feature map의 strongest response 위치와 입력 이미지 내 대응 위치를 나타낸다. 즉 feature map은 단순 feature 값만이 아니라 spatial location 정보도 유지하고 있다.
2.2 The Spatial Pyramid Pooling Layer
Convolution layer는 입력 크기에 상관없이 동작할 수 있지만, 출력되는 feature map의 크기는 입력 이미지 크기에 따라 달라진다. 반면 classifier(SVM/softmax)나 fully connected layer는 고정 길이의 vector를 필요로 한다. 논문은 이러한 고정 길이 vector를 생성하기 위해 Bag-of-Words(BoW) 방식과 Spatial Pyramid Pooling(SPP)을 사용한다. 기존 BoW 방식은 이미지 전체의 feature를 하나로 pooling하여 고정 길이 vector를 만든다. 하지만 이 방식은 spatial information(공간 정보)을 거의 유지하지 못한다는 한계가 있다. 반면 Spatial Pyramid Pooling은 이미지를 여러 단계(level)의 spatial bin으로 나누어 pooling을 수행한다. 각 spatial bin의 크기는 입력 이미지 크기에 비례하여 결정되기 때문에, 입력 이미지 크기가 달라도 항상 동일한 개수의 bin을 생성할 수 있다. 즉 최종 output dimension은 항상 고정된다. 그래서 기존 CNN의 마지막 pooling layer를 SPP로 교체한다.
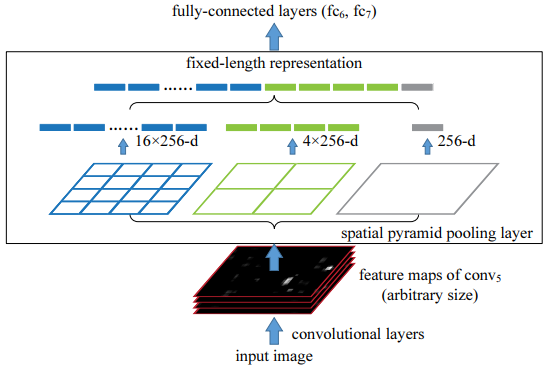
figure3은 SPP 구조를 설명한다. SPP layer는 conv5 feature map을 여러 단계의 spatial bin으로 나누어 pooling한다. 예를 들어 1x1,2x2,4x4 각 영역에서 max pooling을 수행하고 결과를 concat해 하나의 고정길이 vector를 만든다.
-> conv5 filter 개수 : 256 / pyramid level 전체 bin 수 : (1x1 + 2x2 + 4x4) = M / 최종 output dimension : 256 x M
-> 입력 이미지 크기 달라져도 spatial bin 개수는 동일, output vector 길이도 동일하게 유지된다.
논문은 SPP의 또 다른 장점으로 다양한 입력 scale을 사용할 수 있다는 점을 설명한다. 입력 scale이 달라지면 같은 filter라도 서로 다른 scale의 feature를 추출하게 된다. 이는 전통적인 computer vision에서 SIFT feature를 여러 scale에서 추출하던 방식과 유사하다. scale 정보가 CNN 성능 향상에도 중요한 역할을 한다. 또한 pyramid의 가장 coarse한 level은 전체 이미지를 하나의 bin으로 pooling하는데, 이는 사실상 global pooling과 동일하다. 하지만 global pooling과 달리 muti-level spatial 정보를 함께 사용한다는 차이가 있다.
2.3 Training the Network
이론적으로는 앞에서 설명한 SPP-net 구조를 일반적인 back-propagation 방식으로 학습할 수 있으며, 입력 이미지 크기가 달라도 학습이 가능하다. 하지만 실제 GPU 기반 구현(cuda-convnet, Caffe 등)은 고정 크기 입력 이미지에 최적화되어 있다. 따라서 논문은 기존 fixed-size GPU 구현을 유지하면서도 SPP의 장점을 활용할 수 있는 학습 방법을 제안한다.
Sigle-size training
먼저 기존 방식처럼 하나의 고정 입력 크기를 사용하는 경우 설명. 여기서 224x224 crop은 데이터 증강을 위한 것이다. 입력 이미지 크기가 정해지면 conv5 feature map 크기도 고정, spatial pyramid pooling의 bin 크기도 미리 계산 가능하다. 예를 들어 conv5 feature map 크기 = 13×13, pyramid level = n×n이면 pooling window 크기는 a/n이고 stride도 a/n이다.

Figure 4는 cuda-convnet 스타일로 구현된 3-level pyramid pooling 예시이다. SPP layer는 단순 pooling 하나가 아니라 여러 크기의 pooling 결과를 동시에 사용하는 구조이다. single-size taning의 주요 목적은 multi-level pooling behavior 구현, spatial pyramid 효과 활용이다. 즉 입력 크기는 고정이지만 여러 spatial level pooling, 다양한 spatial 정보 유지 효과를 얻을 수 있다.
Multi-size training
SPP-net은 원래 다양한 크기의 이미지를 처리하기 위해 설계되었다. 따라서 논문은 학습 단계에서도 다양한 입력 크기를 사용하는 multi-size training 방법을 제안한다. 예를 들어 224x224, 180x180 두가지 입력 크기를 사용한다. 중요한 점은 단순히 crop을 사용하는 것이 아니라 같은 영역을 resize하여 서로 다른 resolution을 생성하는 것이다. parameter를 공유하고 scale invariance 증가, overfitting 감소한다.
-> 입력이 달라지면 conv5 했을 때 feature map의 크기가 달라지는데 SPP는 이와 상관 없이 output vector를 생성한다.
학습 과정
1. 한 epoch 동안 224×224 network 학습
2. 다음 epoch에서 180×180 network 학습
3. parameter는 그대로 유지
4. 반복 수행
-> 입력 크기만 바뀌고 network wight는 공유된다. 이 방식으로 기존 single-size training과 비슷한 속도로 수렴한다.
중요한 점은 sigle-size / multi-size taining은 학습 단계에서만 필요한 구현 방법으로 테스트 단계에서는 SPP-net을 arbitrary image size에 바로 적용 가능하다.
3. SPP-NET FOR IMAGE CLASSIFICATION
3.1 Experiments on ImageNet 2012 Classification
먼저 SPP-net의 이미지 분류(image classification) 성능을 평가하기 위해 ImageNet 2012 데이터셋에서 실험을 수행한다. 학습은 기존 CNN 연구들의 방법을 따라 진행하였다. 입력 이미지는 먼저 짧은 변(shorter side)이 256이 되도록 resize한 뒤, 그 이미지에서 224×224 crop을 추출한다. Crop 위치는 중앙, 네 개의 코너 중 하나를 사용한다. 또한 data augmentation도 사용하였다. FC layer에는 dropout을 적용하고 lr은 처음 0.01로 시작하고 error가 더이상 감소하지 않으면 10배씩 감소시킨다. 학습 시간은 약 2~4주이다.
3.1.1 Baseline Network Architectures
SPP의 효과가 특정 CNN 구조에서만 나타나는 것이 아니라는 점을 보기 위해 여러 종류의 CNN architecture를 사용해 실험한다. filter 크기, network depth, stride, feature map 크기 등이 서로 다른 다양한 CNN에서 SPP를 적용해본다. 논문은 총 네가지 baseline architecture를 사용한다.
ZF-5 : Zeiler & Fergus의 “fast” 모델 기반 architecture, convolution layer 5개 사용, 비교적 작은 모델, 빠른 연산 가능
Convnet*-5 : AlexNet 구조 수정한 architecture, pooling layer가 conv1, conv2 뒤가 아니라 conv2,conv3 뒤로 이동
Overfeat-5 / Overfeat-7 : Overfeat architecture 기반 모델, 더 큰 feature map 사용, conv3 이후 filter 개수 증가, deeper network 구조라는 특징이 있다. 숫자는 conv layer 갯수

Overfeat 계열이 더 큰 feature map을 유지한다는 것을 알 수 있다. 논문은 baseline 모델에서 마지막 pooling layer 이후 6×6 feature map 생성, 그 뒤 fully connected layer(fc6, fc7), 마지막 softmax classifier가 이어진다고 설명한다. SPP-net은 이 마지막 pooling 부분을 SPP layer로 교체하는 구조이다. 또한 논문은 자신들이 재현(reproduce)한 ZF-5 결과가 원 논문보다 더 좋았다고 설명한다. 그 이유는 crop 방식 떄문이라고 한다. 기존 방식은 중앙 256×256 영역 기준으로 crop했지만, 논문은 전체 이미지 기준 corner crop을 사용하여 더 좋은 성능을 얻었다고 설명한다.
3.1.2 Multi-level Pooling Improves Accuracy
먼저 single-size training 환경에서 SPP의 효과를 실험한다. 여기서는 학습과 테스트 모두 224×224 입력 이미지를 사용한다. SPP-net에서는 convolution layer 구조는 baseline network와 동일하게 유지하고, 마지막 pooling layer만 Spatial Pyramid Pooling(SPP) layer로 교체한다. 논문은 실험에서 4-level pyramid를 사용한다. -> 6x6, 3x3, 2x2, 1x1 총 50개 spatial bin
또한 공정한 비교를 위해 기존 CNN과 동일한 standard 10-view testing 한다.

기존 CNN과 SPP 적용 모델의 classification error 피교한 table2. 결과 보면 모든 architecture에서 성능이 향상되었다. 특히 가장 성능이 높은 network일수록 improvement가 더 크게 나타난다. 중요한 점은 입력 이미지 크기 동일하고 10-view testing이 동일하여 기존 CNN과 거의 같은 조건을 사용했다는 것이다. 따라서 성능 향상은 오직 multi-level pooling 때문이다.
또다른 실험은 4-level pyramid에 {4×4, 3×3, 2×2, 1×1}로 총 30bin이다. 흥미로운 점은 기존보다 parameter 수가 더 적다는 것이다. 왜냐하면 36x256 -> 30x256으로 감소하기 때문이다. 하지만 성능은 여전히 기존 CNN보다 좋았다.
3.1.3 Multi-size Training Improves Accuracy
Table 2의 (c)는 multi-size taining 결과를 보여준다. 실험결과, 모든 network architecture에서 error가 추가적으로 감소하였다. 이러한 결과는 다양한 입력 scale 학습과 scale invariance 증가 덕분이라고 한다.
-> 모델이 큰 객체, 작은 객체, 다양한 resolution에 더 잘 적응할 수 있게 된것
또다른 방식도 실험한다. 입력 s를 [180,224] 범위에서 랜덤하게 선택하여 epoch마다 임의의 입력 크기를 사용한다. 하지만 실험 결과 두 개의 고정 크기를 번갈아 사용하는 방식이 더 좋은 성능을 보였다. 이유는 테스트 입력 크기(224)가 random 방식에서는 상대적으로 적게 등장했기 때문이다. 하지만 random 방시 역시 single 보다는 더 좋은 결과를 보였다.
3.1.4 Full-image Representations Improve Accuracy
이번에는 crop image가 아니라 full-image representation의 효과를 실험했다. 이미지의 짧은 변(min(w,h))을 256으로 resize하여 aspect ratio 유지, 이미지 전체(full image)를 SPP-net에 입력하였다.
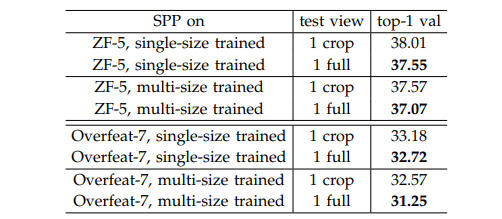
결과를 보면 full-image representation이 더 좋은 성능을 보인다. -> 이미지 전체를 사용하는 것이 classification accuracy 향상에 도움이 된다. 이유는 crop 방식은 객체 일부가 잘릴 수 있지만 full은 전체 cotent 유지 가능이라고 설명한다. 또한 square로만 학습되었음에도 다양한 aspect ratio 이미지에도 잘 generalize 된다는 점이 흥미롭다. -> 입력 비율 변화와 다양한 이미지 형태에도 강인하다.
3.1.5 Multi-view Testing on Feature Maps
object detection 방식에서 아이디어를 얻어, feature map 위에서 직접 multi-view testing을 수행하는 방법을 제안한다. 기존 multi-view testing은 이미지 crop 여러 개 생성 -> crop마다 CNN 다시 수행하는 방식. 하지만 SPP-net은 convolution feature map을 한 번만 계산한 뒤, feature map 위에서 다양한 window(view)를 추출하여 pooling할 수 있다. 즉 convolution 연산을 반복할 필요가 없다.
입력 이미지 resize -> 전체 이미지에 대해 convolution 수행 -> feature map 생성 -> feature map 위에서 여러 window(view) 선택 -> 각 window에 대해 SPP pooling 수행 -> fc layer 통과 후 score 계산 -> 여러 view의 score 평균
여러 crop 여러번 만드는 대신 feature map 하나를 공유하고 pooling만 반복하는 방식이다.
먼저 standard 10-view testing을 feature map 방식으로 구현한다. 기존엔 crop 10 생성했다면 SPP는 feature map에서 해당 위치만 pooling -> 결과적으로 기존과 거의 동일한 정확
이 후 더 많은 scale과 view를 사용한다. -> 결과적으로 error 감소
3.1.6 Summary and Results for ILSVRC 2014
마지막으로 ImageNet classification 결과를 기존 state-of-the-art 모델들과 비교한다. 공정한 비교를 위해 single만 비교.

결과적으로 SSP 모델이 기존 모델들보다 더 좋은 성능을 냈다. 특히 multi-scale, multi-view, full-image를 함께 사용했을 때 가장 좋을 결과를 얻었다. 그리고 이 모델을 ILSVRC 2014에 제출하였다.

결과적으로 classification 부문 3위하였다. SPP는 특정 architecture 전용 기술이 아니라 일반적인 CNN improvement technique라고 주장한다.
3.2 Experiments on VOC 2007 Classification
SPP-net이 ImageNet뿐 아니라 다른 데이터셋에서도 좋은 성능을 보이는지 확인하기 위해 Pascal VOC 2007 classification 실험을 수행한다. SPP-net은 이미지 전체(full-view image) representation을 생성할 수 있기 때문에, ImageNet에서 pre-train된 network를 그대로 사용하여 target dataset feature extraction에 활용한다. 이후 추출된 feature를 사용해 SVM classifier를 다시 학습한다. 여기서 중요한 점은 fine-tuning, multi-view testing 사용 안 한다는 것이다.
-> 단순히 ImageNet pre-trained CNN 사용, feature extraction, SVM 학습만 수행하였다.
먼저 baseline 실험을 수행하는데 ZF-5 without SPP을 사용해
- 이미지 짧은 변을 224로 resize
- 중앙(center) 224×224 crop 사용
이 후 각 layer의 feature를 추출해 SVM을 학습한다. 결과적으 deeper layer일수록 성능이 더 좋다.

Table 6은 다양한 layer와 입력 방식에 따른 classification mAP를 비교한다.
(a) : no SPP, crop image 사용
(b) : SPP 적용, 여전히 crop image 사용
(c) : SPP 적용, full-image representation 사용
(d) : 더 큰 image scale 사용
(e) : 더 깊은 network 사용
먼저 (a)와 (b)를 비교하면 crop 방식 그대로 사용했음에도 SPP 적용 시 성능 향상이 나타난다.
-> multi-level pooling 자체가 VOC classification에서도 효과적이라는 의미이다.
다음으로 논문은 crop 대신 full-image representation을 사용한다. 이미지 짧은 변을 224로 resize, 이미지 전체를 SPP-net에 입력한다. 결과적으로 성능이 크게 향상되었다.
-> 이미지 전체 정보를 유지하는 것이 classification에 더 유리하다는 것을 보여준다.
추가로 입력 scale도 변경해본다. 결과적으로 성능이 향상되었다. 이유로는 VOC dataset 객체는 ImageNet보다 상대적으로 작고 더 큰 scale 사용 시 object detail 유지 가능하기 떄문이다.
-> dataset마다 적절한 object scale이 다를 수 있음, SPP-net은 다양한 scale 처리 가능하다는 장
3.3 Experiments on Caltech101
Caltech101 데이터셋은 총 9,144장의 이미지와 102개의 카테고리(배경 포함)로 구성되어 있다. 논문에서는 각 카테고리마다 30장의 이미지를 학습에 사용하고, 최대 50장의 이미지를 테스트에 사용하였다. 또한 random split을 10번 반복하여 평균 classification accuracy를 계산하였다.

Table 7은 Caltech101에서의 classification 결과를 보여준다. 논문은 기존 CNN(no SPP), SPP 적용 모델, crop image, full-image representation 등을 비교하였다. 실험 결과 SPP를 적용한 경우 기존 CNN보다 더 높은 accuracy를 보였으며, 특히 full-image representation을 사용할 때 성능이 더욱 향상되었다. 또한 deeper network인 Overfeat-7을 사용한 경우 가장 높은 accuracy인 93.42%를 기록하였다.
논문은 Pascal VOC 2007과 비교했을 때 Caltech101에서는 fc layer보다 SPP pooled feature가 더 좋은 성능을 보였다고 설명한다. 이는 Caltech101 category가 ImageNet과 상대적으로 덜 유사하기 때문에, ImageNet에 특화된 deeper layer feature보다 spatial information을 유지하는 pooled feature가 더 잘 generalize되기 때문이라고 분석한다. 또한 입력 scale 224가 가장 좋은 성능을 보였는데, 이는 Caltech101 객체 크기가 ImageNet과 유사하기 때문이라고 설명한다.
논문은 crop 방식 외에 warp 방식도 비교하였다. Warp 방식은 이미지를 강제로 224×224로 resize하는 방법인데, 이 경우 geometric distortion이 발생할 수 있다. 실험 결과 warped image 방식보다 full-image SPP 방식이 더 높은 accuracy를 기록하였다. 마지막으로 Table 8에서는 기존 state-of-the-art 방법들과 비교하였으며, SPP-net은 93.42% accuracy를 기록하여 당시 최고 성능보다 약 4.88% 높은 결과를 달성하였다.
4 SPP-NET FOR OBJECT DETECTION
논문은 SPP-net이 image classification뿐 아니라 object detection에서도 매우 효과적이라고 설명한다. 기존 R-CNN은 약 2,000개의 candidate window(region proposal) 각각에 대해 CNN을 반복 수행해야 했기 때문에 detection 속도가 매우 느렸다. 반면 SPP-net은 전체 이미지에 대해 convolution feature map을 한 번만 계산한 뒤, feature map 위에서 각 candidate window 영역만 선택하여 Spatial Pyramid Pooling을 수행한다. 즉 convolution feature map을 여러 region이 공유하기 때문에 연산량을 크게 줄일 수 있다.
또한 기존 Overfeat detection은 predefined window size만 사용할 수 있었지만, SPP-net은 arbitrary window size를 자유롭게 사용할 수 있다는 장점이 있다. 논문은 이러한 구조가 기존 computer vision의 feature-map 기반 방법들과 유사하지만, deep convolution feature를 arbitrary region 단위로 pooling한다는 점이 핵심 차별점이라고 설명한다.

Figure 5는 SPP-net의 object detection 구조를 보여준다. 먼저 전체 이미지에 대해 convolution feature map을 계산한 뒤, candidate window에 해당하는 feature map 영역만 선택하여 Spatial Pyramid Pooling을 수행한다. 이후 pooled feature를 fully connected layer에 입력하여 object classification을 수행한다. 즉 convolution feature map을 여러 candidate region이 함께 공유한다는 점이 핵심이다. 이 방식 덕분에 detection 과정의 연산량이 크게 감소한다.
4.1 Detection Algorithm
논문은 selective search를 이용해 약 2,000개의 candidate window를 생성한 뒤, 전체 이미지에 대해 convolution feature map을 한 번만 계산한다. 이후 각 candidate window에 대해 1×1, 2×2, 3×3, 6×6의 4-level spatial pyramid pooling을 수행하여 fixed-length feature vector를 생성한다. 생성된 feature는 fully connected layer와 binary SVM classifier에 입력된다.
논문은 multi-scale feature extraction도 적용하였다. 입력 이미지를 여러 scale로 resize한 뒤 feature map을 계산하고, candidate window 크기에 가장 적절한 scale의 feature map을 선택하여 pooling을 수행한다. 또한 fine-tuning과 bounding box regression을 적용하여 detection accuracy를 향상시켰다.
4.2 Detection Results
Pascal VOC 2007 데이터셋에서 SPP-net의 detection 성능을 평가하였다. 실험 결과 SPP-net은 기존 R-CNN과 비슷하거나 더 높은 detection accuracy를 보이면서도 훨씬 빠른 속도를 달성하였다. 특히 fine-tuning과 bounding box regression을 함께 사용한 경우 59.2% mAP를 기록하여 기존 R-CNN보다 더 높은 성능을 보였다.

Table 9는 Pascal VOC 2007 detection 결과를 비교한 표이다. 결과적으로 SPP-net은 detection accuracy는 유지하거나 향상, feature extraction 속도는 크게 개선하였다. 특히 convolution 연산을 한 번만 수행하고 feature map을 공유하기 때문에 detection 속도가 매우 빨라졌다.
추가로 속도 비교도 수행하였다. 기존 R-CNN은 candidate window마다 CNN을 반복 수행해야 했기 때문에 convolution feature extraction에 약 14초 이상이 필요하였다. 반면 SPP-net은 convolution feature map을 공유하기 때문에 약 0.1~0.3초 수준만 필요하였다. 즉 약 24배~102배 빠른 detection 속도를 달성하였다.

Table 10은 동일한 pretrained model(ZF-5)을 사용하여 R-CNN과 SPP-net을 직접 비교한 결과이다. SPP-net은 거의 동일하거나 더 높은 mAP를 기록하면서도 훨씬 빠른 속도를 유지하였다. 논문은 이를 통해 SPP-net의 multi-level pooling과 convolution feature map reuse가 매우 효과적이라는 점을 보여준다.
4.3 Complexity and Running Time
SPP-net의 가장 큰 장점 중 하나로 연산량 감소와 빠른 detection 속도를 설명한다. 기존 R-CNN은 약 2,000개의 candidate window 각각에 대해 CNN을 반복 수행해야 했기 때문에 convolution 연산량이 매우 컸다. 반면 SPP-net은 전체 이미지에 대해 convolution feature map을 한 번만 계산한 뒤, 각 region에서는 pooling만 수행한다. 따라서 가장 계산 비용이 큰 convolution 연산을 반복하지 않아도 된다.
논문은 convolution layer의 계산량이 fully connected layer보다 훨씬 크다고 설명한다. 특히 deeper convolution layer일수록 연산량이 매우 커지는데, R-CNN은 이러한 convolution 연산을 candidate window 개수만큼 반복 수행하기 때문에 비효율적이다. 반면 SPP-net은 convolution feature map을 공유하기 때문에 complexity가 크게 감소한다.
실험 결과 SPP-net은 GPU 환경에서 feature extraction 속도를 매우 크게 향상시켰다. 기존 R-CNN은 한 이미지 처리에 약 10~14초 이상이 필요했지만, SPP-net은 약 0.1~0.3초 수준만 사용하였다. 즉 약 24배~102배 빠른 detection 속도를 달성하였다. 논문은 이러한 속도 향상이 convolution feature map reuse 덕분이라고 설명한다.
또한 SPP-net은 feature map 기반 pooling 구조를 사용하기 때문에, deeper network에서도 효율적으로 동작할 수 있다고 설명한다. 논문은 이러한 구조가 이후 Fast R-CNN과 ROI Pooling 같은 detection framework 발전의 기반이 되었다고 강조한다.

Table 11은 R-CNN과 SPP-net의 running time을 비교한 표이다. 논문은 convolution time, fully connected time, feature extraction time, 전체 detection 시간 등을 비교하였다. 결과를 보면 기존 R-CNN은 candidate window마다 CNN을 반복 수행하기 때문에 convolution 시간이 매우 크게 나타난다. 반면 SPP-net은 전체 이미지에 대해 convolution feature map을 한 번만 계산하고 이를 여러 region이 공유하기 때문에 연산량이 크게 감소하였다.
특히 R-CNN은 한 이미지 처리에 약 10~14초 정도가 필요했지만, SPP-net은 약 0.1~0.3초 수준만 사용하였다. 즉 SPP-net은 기존 R-CNN보다 약 24배~102배 더 빠른 detection 속도를 달성하였다. 논문은 이러한 속도 향상이 convolution feature map reuse 덕분이라고 설명한다. 즉 가장 계산량이 큰 convolution 연산을 한 번만 수행하고 여러 candidate window가 공유하도록 만든 것이 핵심 아이디어이다.
4.4 Model Combination for Detection
논문은 CNN 기반 classification에서 model combination(ensemble)이 매우 효과적인 방법이라는 점을 object detection에도 적용하였다. 저자들은 동일한 network structure를 사용하되 random initialization만 다르게 하여 또 다른 network를 ImageNet에서 pre-train한 뒤 동일한 detection 알고리즘을 수행하였다. Table 12의 SPP-net(2)가 이 두 번째 모델의 결과이다. 두 모델은 비슷한 성능을 보였으며, 두 번째 모델은 20개 category 중 11개 category에서 첫 번째 모델보다 더 좋은 결과를 나타냈다.
논문은 이후 두 모델을 결합하는 방법도 제안한다. 먼저 두 모델 각각이 test image의 candidate window들에 대해 score를 계산한다. 이후 두 모델의 candidate window를 합친 뒤 non-maximum suppression(NMS)을 수행한다. 이 과정에서 한 모델이 높은 confidence를 준 window가 다른 모델의 낮은 confidence window를 제거할 수 있다. 실험 결과 model combination 이후 mAP는 59.2%에서 60.9%로 향상되었다. 또한 전체 20개 category 중 17개 category에서 단일 모델보다 더 좋은 성능을 보였다. 논문은 이를 통해 두 모델이 서로 complementary한 특징을 가진다고 설명한다.
저자들은 이러한 complementarity가 주로 convolution layer 차이에서 발생한다고 분석하였다. 실제로 동일한 convolution model을 사용한 채 fine-tuning만 다르게 한 모델들을 결합했을 때는 성능 향상이 거의 나타나지 않았다. 즉 model combination 효과는 convolution feature representation의 차이에서 주로 발생한다는 의미이다.
4.5 ILSVRC 2014 Detection
ILSVRC 2014 detection task는 총 200개의 category로 구성되며, 약 45만 장의 training image, 2만 장의 validation image, 4만 장의 testing image를 포함한다. 논문은 provided-data-only track에 참여하였으며, 여기서는 ImageNet classification용 1000-category training data를 사용할 수 없다.
논문은 detection dataset과 classification dataset 사이의 중요한 차이점 세 가지를 설명한다. 첫 번째는 detection training data 양이 classification training data의 약 1/3 수준이라는 점이다. 두 번째는 detection category 수가 classification의 1/5 수준이라는 점이다. 이를 해결하기 위해 논문은 제공된 subcategory label을 사용하였다. 전체 499개의 subcategory를 이용해 499-category network를 pre-train하였다. 세 번째는 object scale distribution 차이이다. Classification dataset에서는 객체가 이미지의 약 80%를 차지하는 경우가 많지만, detection dataset에서는 약 50% 정도만 차지한다. 이를 해결하기 위해 논문은 입력 이미지를 min(w,h)=400으로 resize하고, object와 50% 이상 overlap되는 224×224 crop만 사용하여 학습하였다.
논문은 이러한 pre-training 전략의 효과도 Pascal VOC 2007에서 검증하였다. 기존 classification pre-training 모델은 43.0% mAP를 기록하였지만, detection dataset만으로 학습한 200-category network는 32.7% mAP로 크게 감소하였다. 이후 499-category network를 사용하자 35.9%로 향상되었고, 추가적으로 min(w,h)=400 설정을 사용하자 37.8%까지 향상되었다. 논문은 이를 통해 deep learning에서 대규모 데이터가 매우 중요하다는 점을 강조한다.
최종적으로 논문은 499-category Overfeat-7 SPP-net을 사용하여 ILSVRC 2014 detection task를 수행하였다. 이후 과정은 VOC 2007 detection과 유사하며, selective search fast mode를 사용하여 candidate window를 생성하였다. 또한 fine-tuning, SVM training, bounding box regression도 함께 적용하였다.
실험 결과 single model은 ILSVRC 2014 test set에서 31.84% mAP를 기록하였다. 이후 논문에서 제안한 model combination 전략으로 6개의 model을 결합하자 최종 mAP는 35.11%까지 향상되었다. 이 결과는 provided-data-only track에서 2위를 기록하였다.
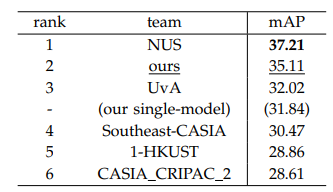
Table 13은 ILSVRC 2014 detection competition 결과를 보여준다. 논문 팀은 35.11% mAP를 기록하여 2위를 달성하였다. 1위는 contextual information을 사용한 NUS 팀으로 37.21% mAP를 기록하였다. 논문은 단일 모델(single model)만 사용한 경우에도 31.84% mAP를 기록했다고 설명한다. 논문은 마지막으로 속도 측면의 장점도 강조한다. SPP-net single model은 GPU 환경에서 한 이미지 처리에 약 0.6초만 사용하였다.
5 Conclusion
논문은 Spatial Pyramid Pooling(SPP)이 서로 다른 scale, size, aspect ratio를 처리하기 위한 매우 유연한 방법이라고 결론짓는다. 기존 deep network에서는 이러한 문제들이 충분히 고려되지 않았지만, SPP-net은 spatial pyramid pooling layer를 이용하여 이를 해결하였다.
SPP-net은:
- image classification
- object detection
모두에서 매우 높은 accuracy를 보였으며, 특히 DNN 기반 object detection 속도를 크게 향상시켰다. 또한 논문은 traditional computer vision에서 오랫동안 사용되던 spatial pyramid와 multi-scale 아이디어가 deep learning 기반 recognition에서도 여전히 중요한 역할을 할 수 있음을 보여준다.